HDFS and YARN
本文主要说明HDFS和MapReduce两门技术的入门使用.因为MapReduce太长,后面就简称MR,我们到官网下载hadoop-2.4.1.tar.gz,并解压,进入到hadoop-2.4.1/etc/hadoop,分别配置以下几个文件
- hadoop-env.sh
- core-site.xml
- hdfs-site.xml
- mapred-site.xml.template(重命名为mapred-site.xml)
- yarn-site.xml
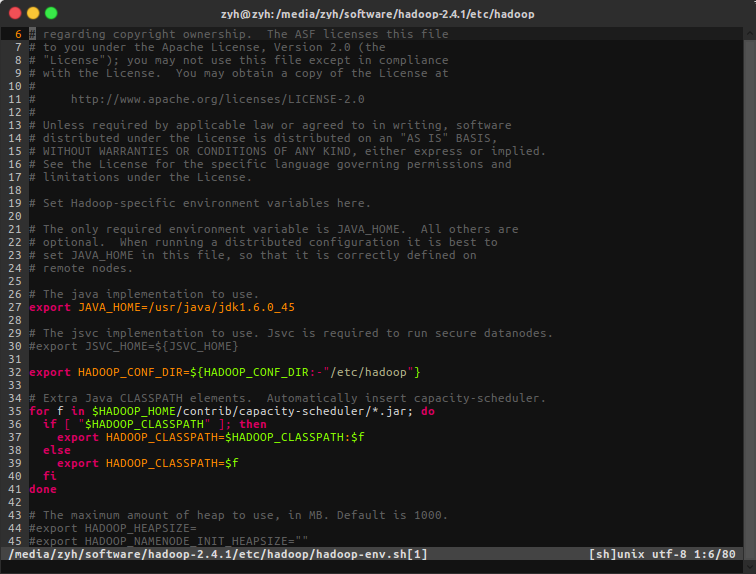
配置 hadoop-env.sh
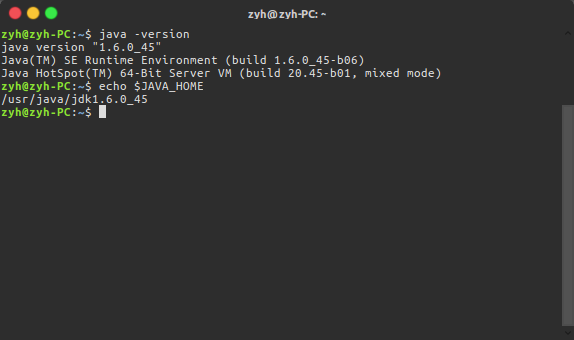
需要到hadoop-env.sh中配置Java环境,值得注意的是在hadoop-env.sh文件中使用的变量名不会生效,我们在这里写死它,查询Java存放路径
ehco $JAVA_HOME
配置 core-site.xml
- fs.defaultFS: 指定HADOOP所使用的文件系统访问的URI
- hadoop.tmp.dir: 指定hadoop运行时产生文件的存储目录
1 | |
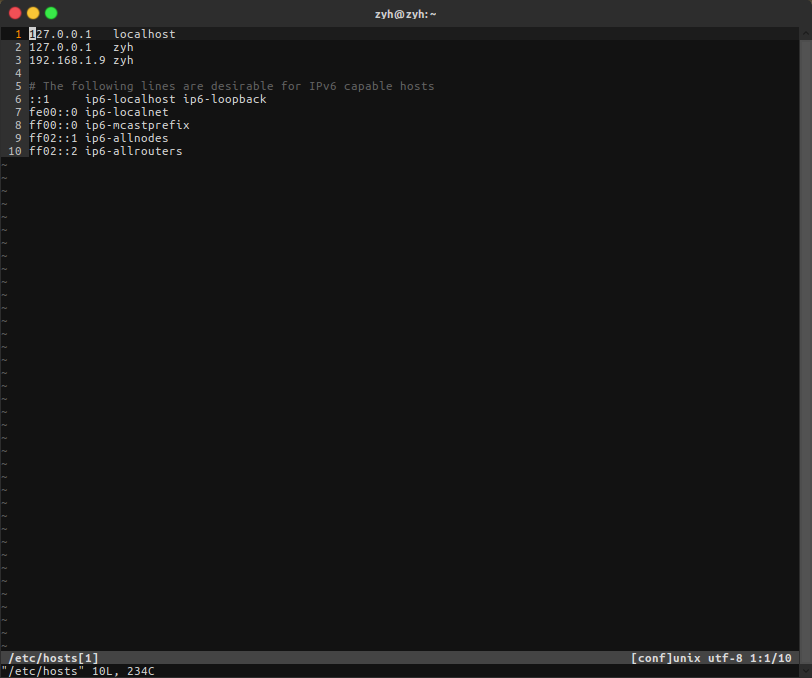
这里hdfs://zyh:9000/中的zyh相当于localhost,因为我在/etc/hosts文件中修改了
配置 hdfs-site.xml
- dfs.replication: 指定HDFS切块(blk)的副本数量
1 | |
配置 mapred-site.xml
- mapreduce.framework.name:指定MR的运行的资源由yarn分配
1 | |
配置 yarn-site.xml
- yarn.resourcemanager.hostname: 指定YARN的ResourceManager的地址,其实就是我本机zyh(127.0.0.1)
- yarn.nodemanager.aux-services: reducer获取数据的方式
1 | |
将hadoop添加到环境变量
1 | |
这个是我本地的profile作参考
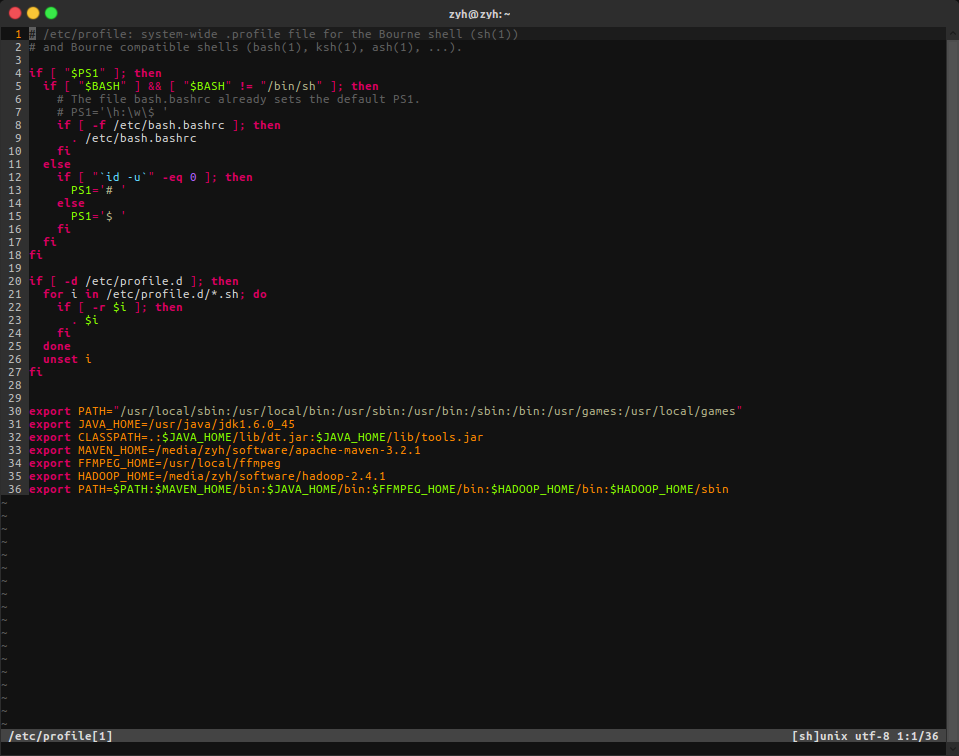
初始化namenode(又叫格式化namenode)
$ hdfs namenode -format (hadoop namenode -format)
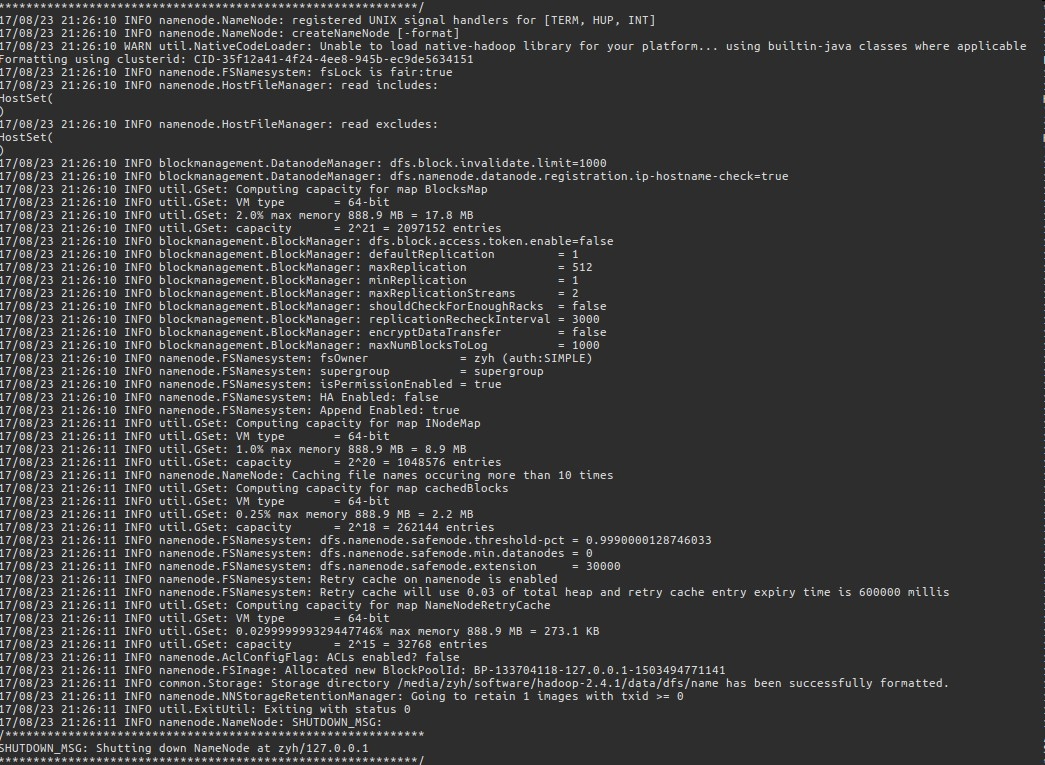
弹出一大片log,英语很nice可以稍微看看,不好的可以键入命令echo $?来校验上一个操作是否正确,如果是0就是正确的
启动hadoop
如果你格式化namenode已成功,就可以运行hadoop了!在hadoop-2.4.1/sbin目录下面,hadoop为我们提供了很多命令
- start-all.sh : 启动dfs和yarn
- start-dfs.sh : 启动dfs
- start-yarn.sh : 启动yarn
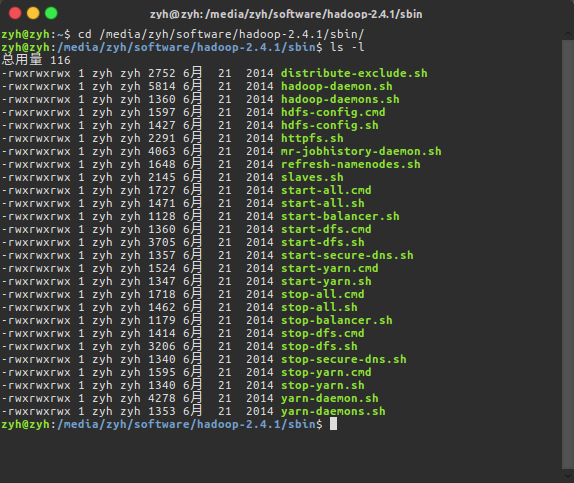
作为入门的新手,我们当然是一步一步启动,先启动HDFS,再启动YARN.并观察启动后的运行状态
启动HDFS
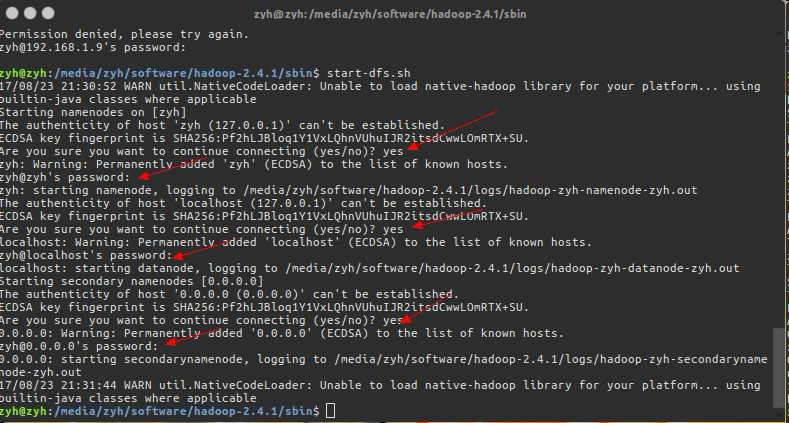
$ sbin/start-dfs.sh
启动报错,如果说本地ssh拒绝访问,那么我们需要安装openssh-server,如果没有报错请无视!
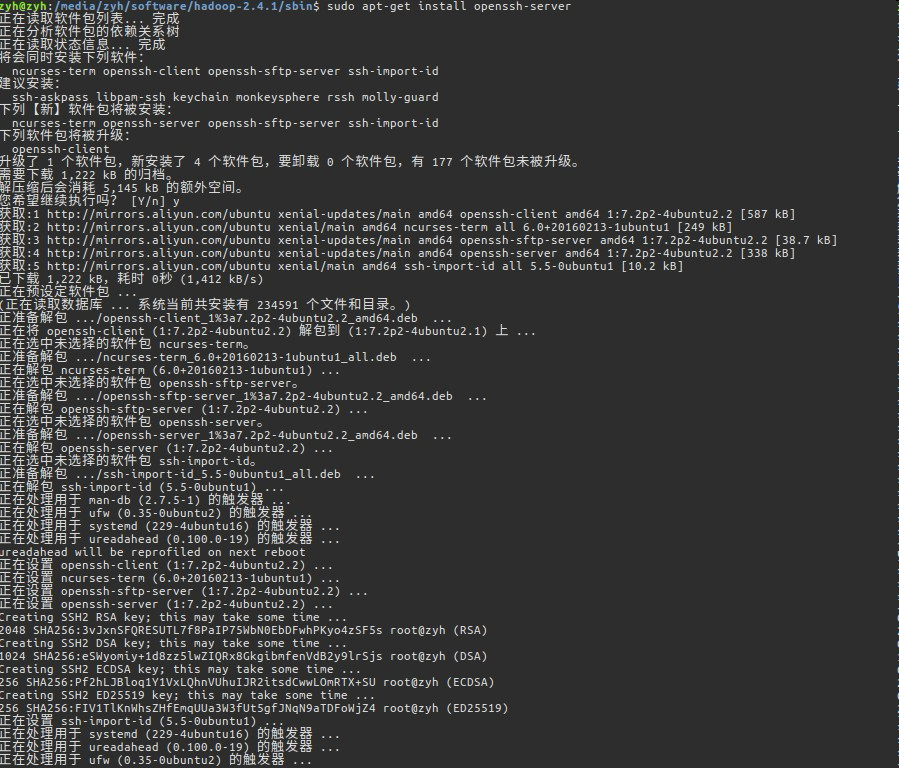
安装后再次键入命令.HDFS会提示会让我们输入很多次密码并确认,因为部署的是分布式系统,尽管我们只使用了一台电脑,但是HDSF不知道,他会使用SSH去访问我们远程的服务器(本例中远程服务器就是本机啦!)之后它会启动一系列进程,这些进程分别是:
- NameNode
- DataNode
- SecondaryNameNode
启动YARN
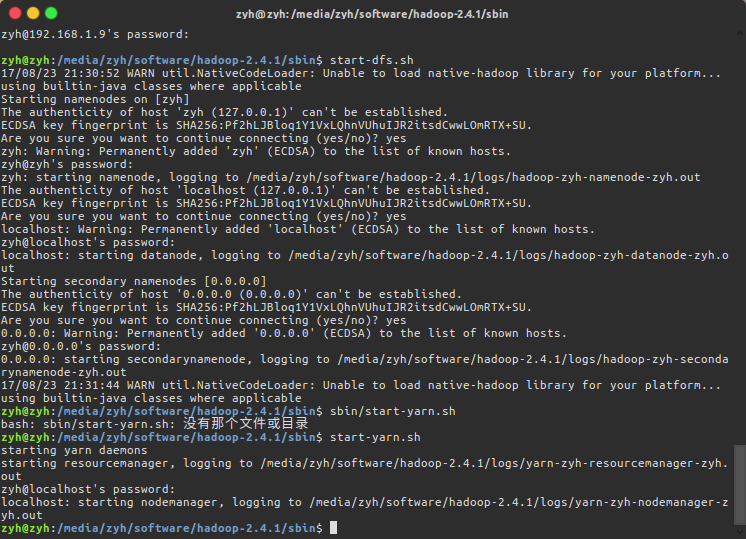
$ sbin/start-yarn.sh
yarn也是一样的一路yes并输入密码即可,yarn会先后开启两个进程,他们分别是
- ResourceManager
- NodeManager
查看启动进程的状态
$ jps
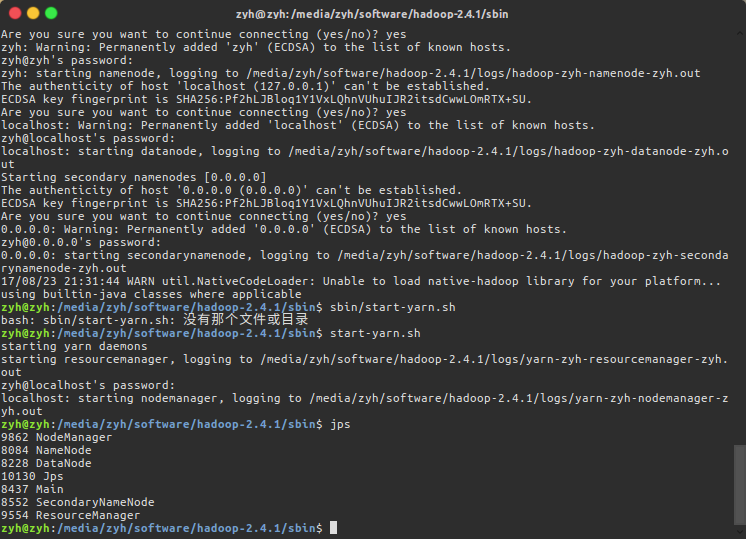
使用HDFS
打开网址http://zyh:50070 (HDFS管理界面),在该界面我们可以查看HDFS的运行状态信息,在Browse the file system一栏中可以查看HDFS目录结构
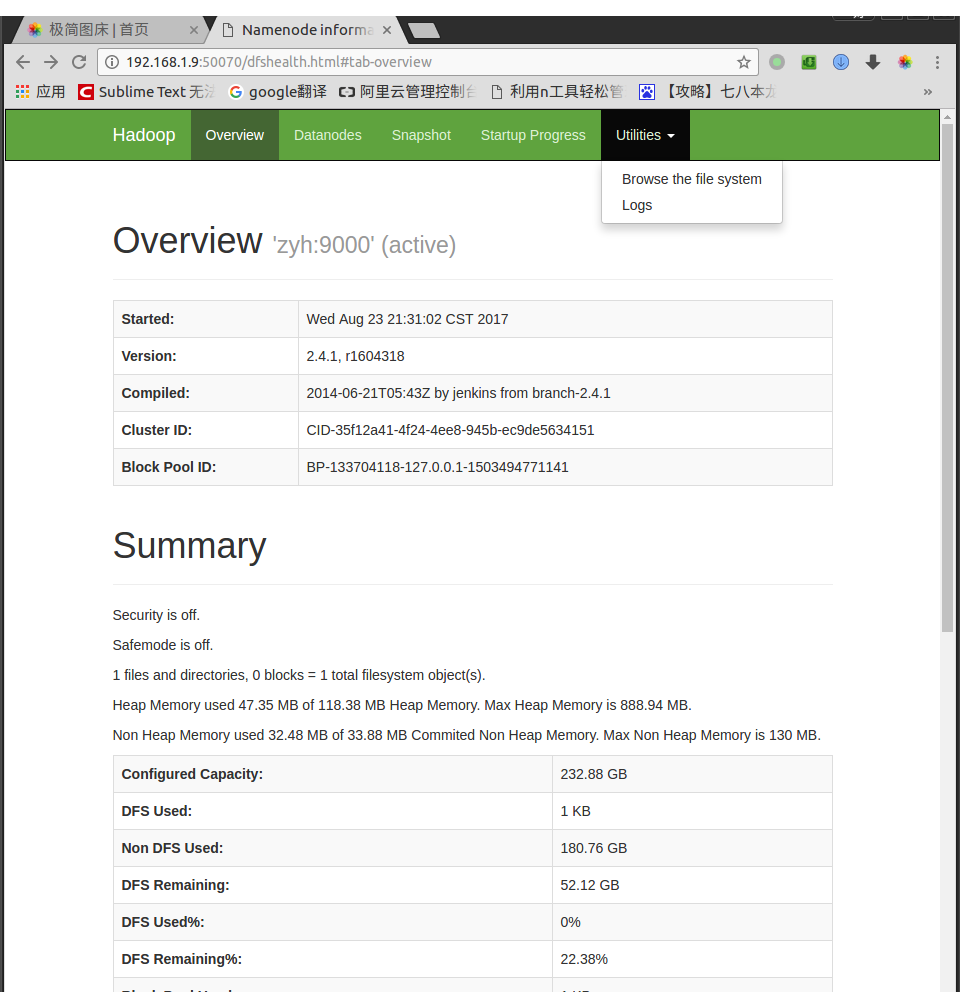
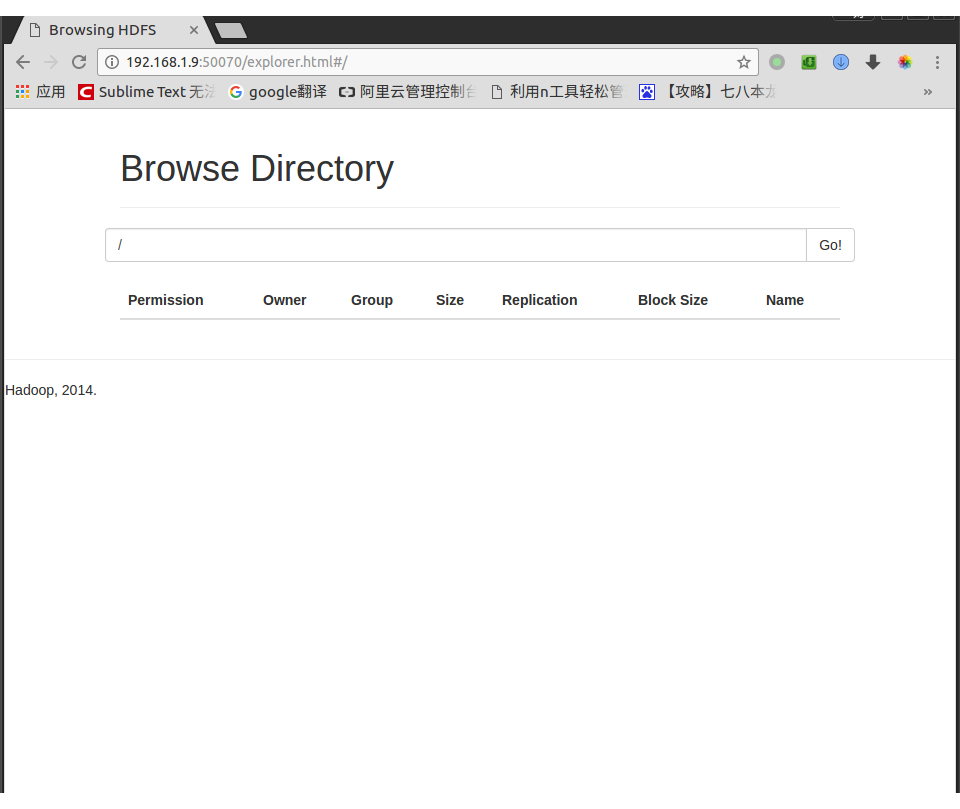
因为我们什么都没有做,所以在Browse Directory下面什么都没有,HDFS的目录结构和linux的目录结构差不多,都是以/为根目录.
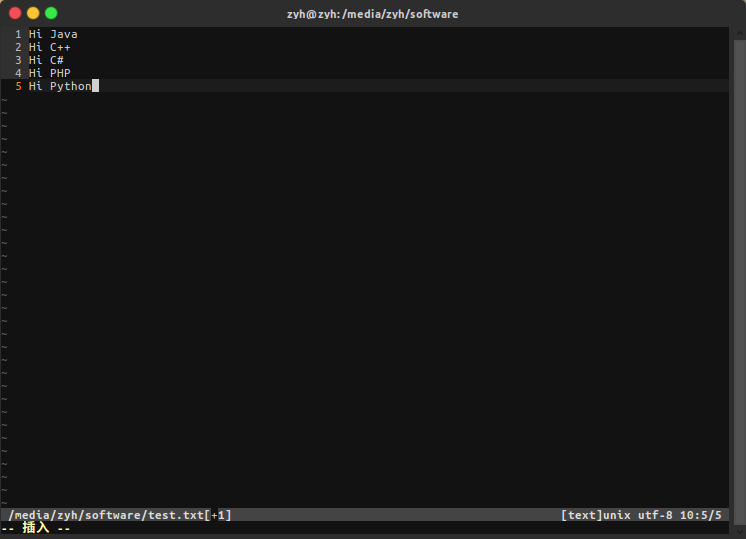
编写test.txt并上传到HDFS中(被上传的文件会被分为若干个切块,分别放于不同的datanode中)
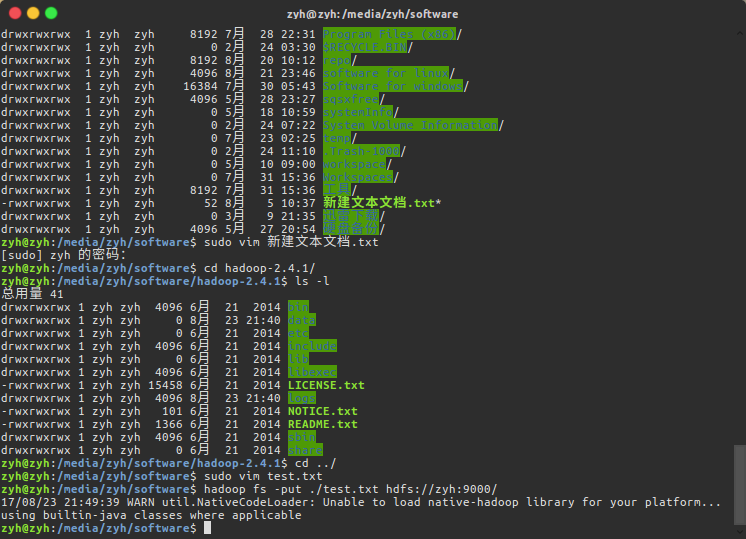
键入命令,将test.txt上传到hdfs上
$ hadoop fs -put test.txt hdfs://zyh:9000/
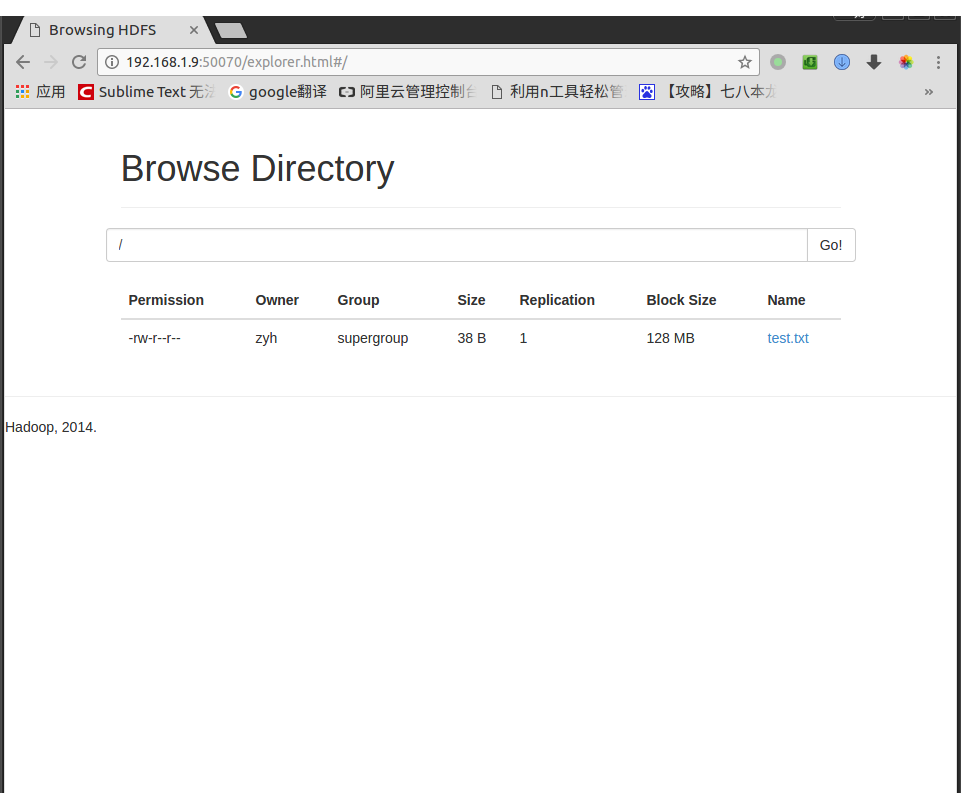
再次打开http://zyh:50070,查看HDFS就会发现多出了一个test.txt文件
使用MR
到hadoop-2.4.1/share/hadoop/mapreduce目录下可以找到hadoop-mapreduce-examples-2.4.1.jar,这个jar是Hadoop为我们编写的mapreduce小例子,我们可以使用它来做一些测试
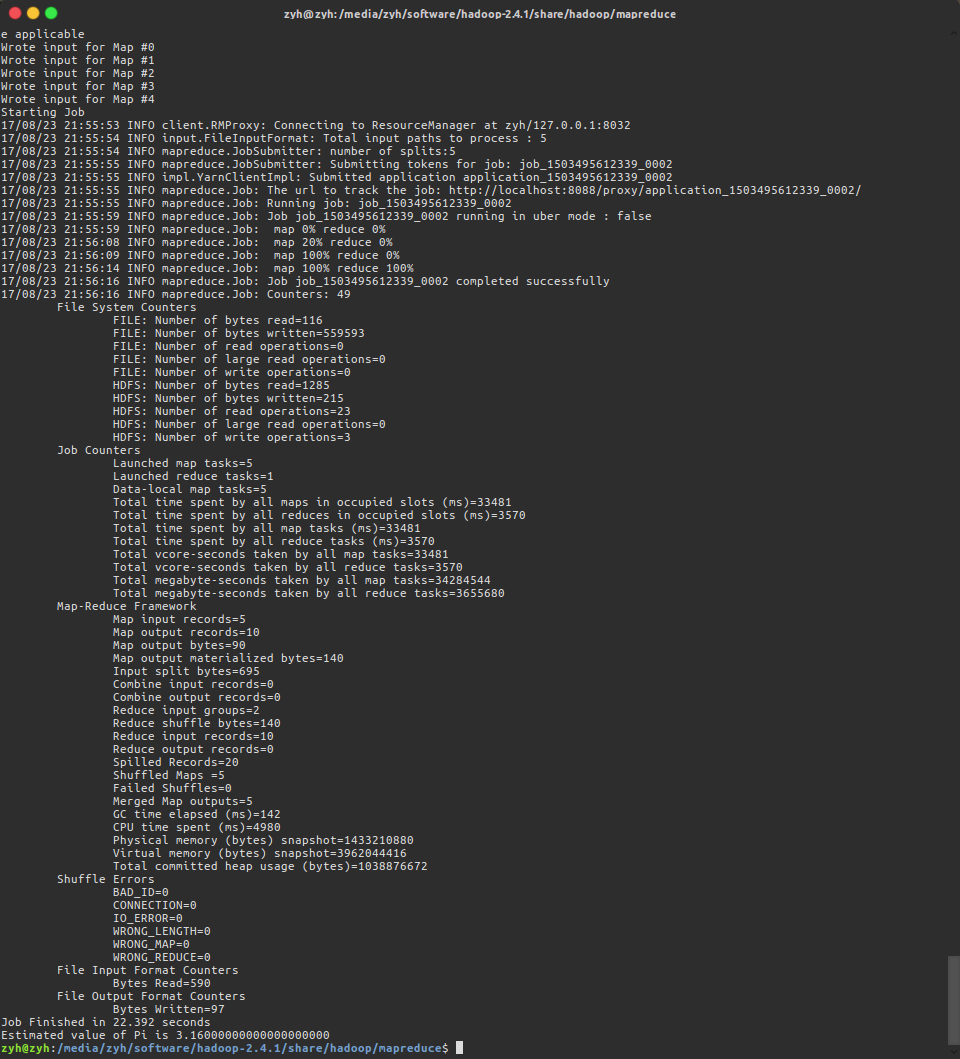
我们使用MR做一些小测试!
- 打印pi的值
到hadoop-mapreduce-examples-2.4.1.jar根目录
- pi : 方法名
- 5 : 参数1
- 100 : 参数2
$ hadoop jar hadoop-mapreduce-examples-2.4.1.jar pi 5 100
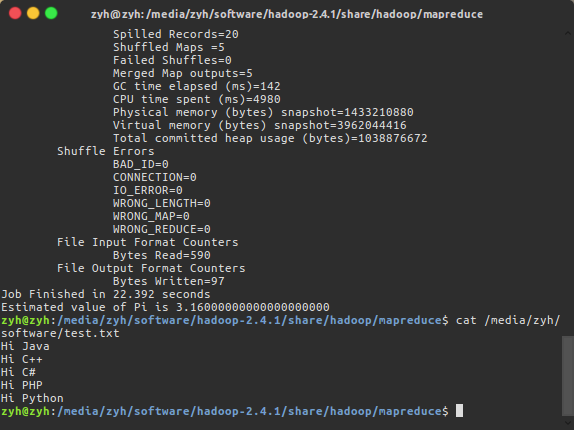
- 统计我们之前test.txt中字符串出现的次数
$ cat test.txt
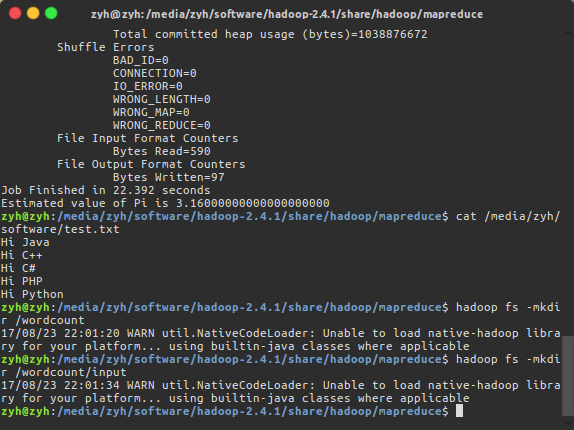
这一次我们在HDFS文件系统中创建一些目录,将test.txt上传到指定目录中去
创建/wordcount/input用来放被统计的文件,值得注意的是我们必须先创建/wordcount,才能再创建/input
$ hadoop fs -mkdir /wordcount
$ hadoop fs -mkdir /wordcount/input
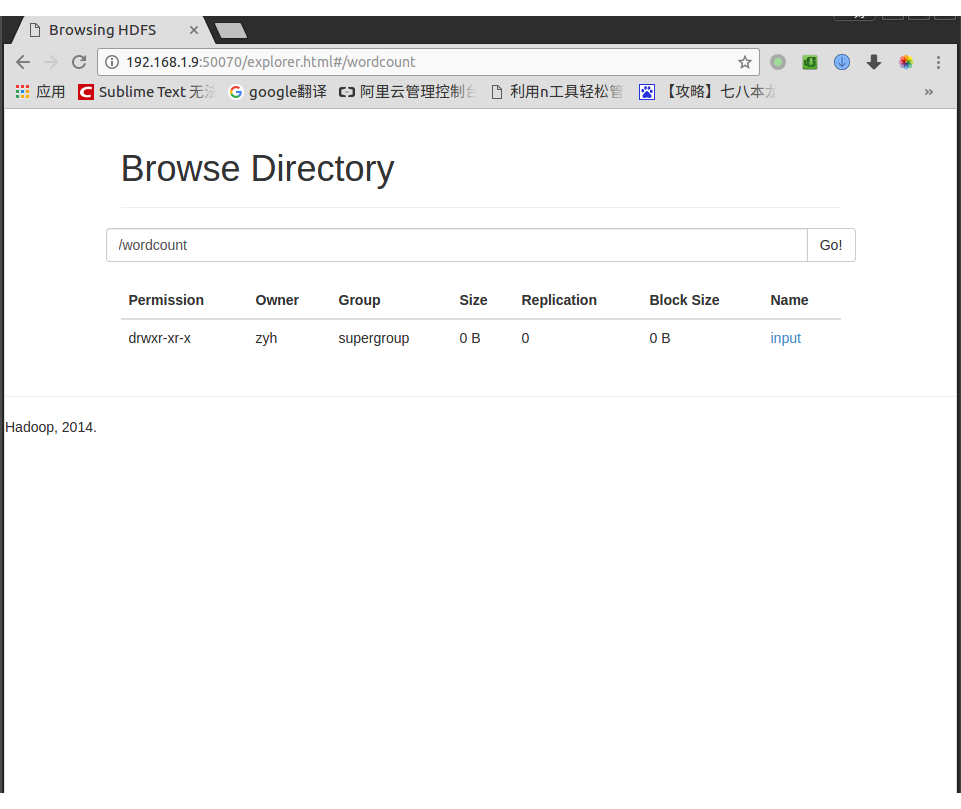
同理创建创建/wordcount/output用来放被统计后的输出文件
$ hadoop fs -mkdir /wordcount
$ hadoop fs -mkdir /wordcount/out
将test.txt文件上传到HDFS文件系统中的input目录
$ hadoop fs -put text.txt /wordcount/input
使用命令对test.txt进行统计,wordcount:指定本次运行的是统计方法,/wordcount/input:指定被统计的文件,/wordcount/out: 指定统计后的输出目录
- wordcount : 方法名
- /wordcount/input : 参数1
- /wordcount/out : 参数2
$ hadoop jar hadoop-mapreduce-examples-2.4.1.jar wordcount /wordcount/input /wordcount/out
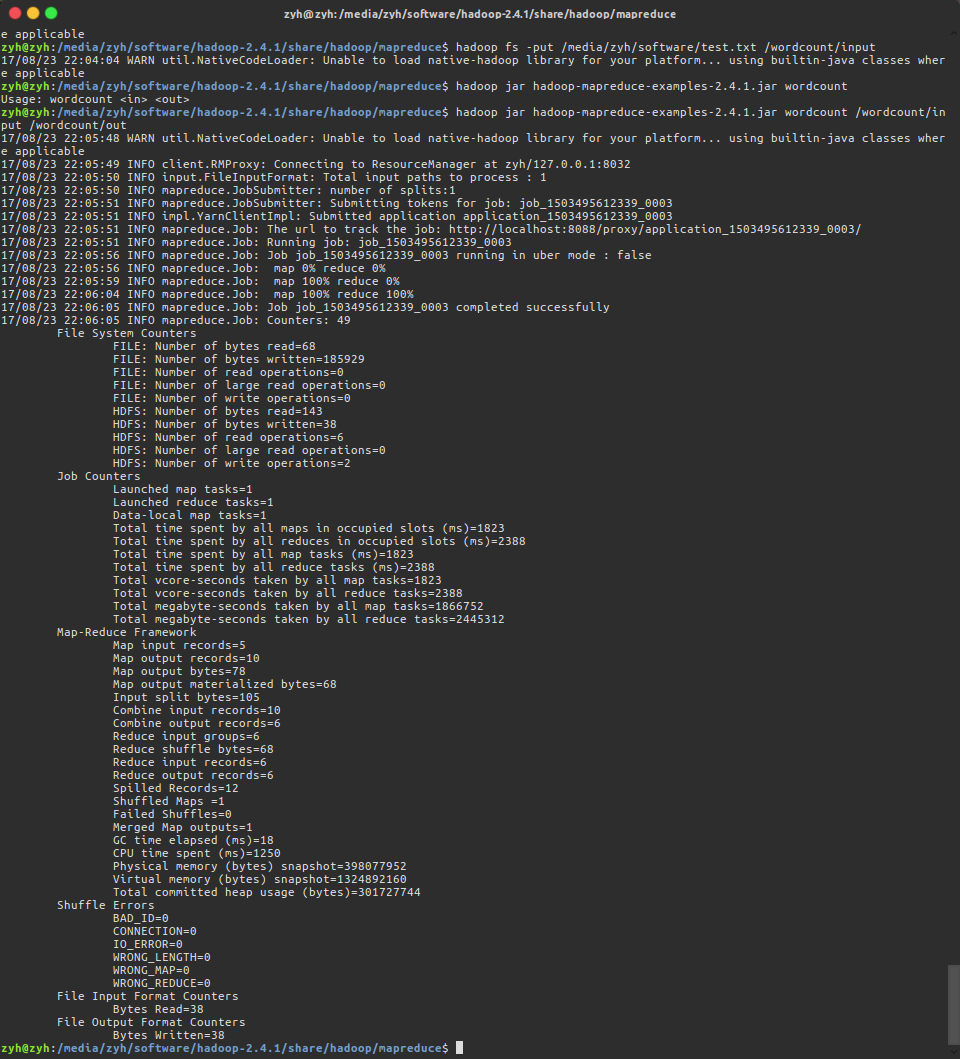
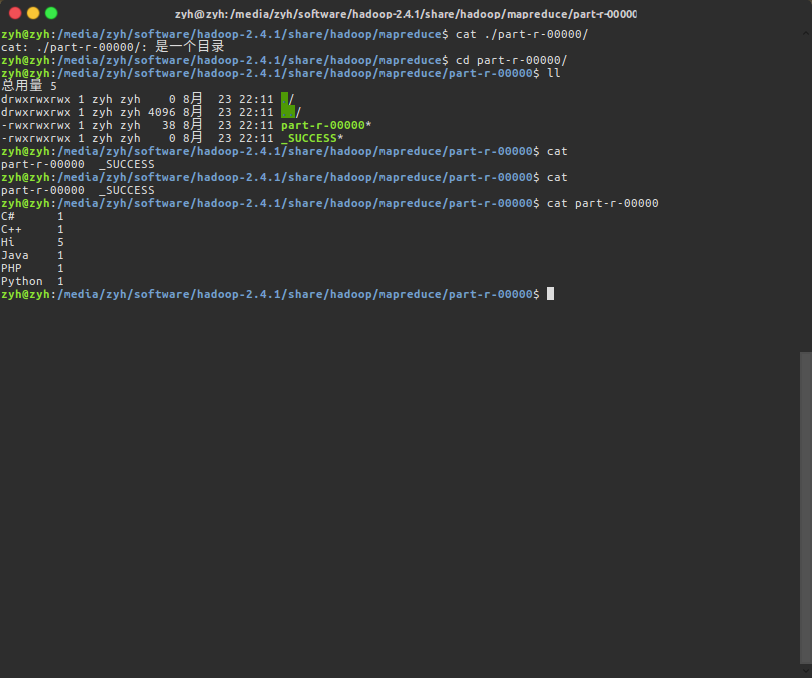
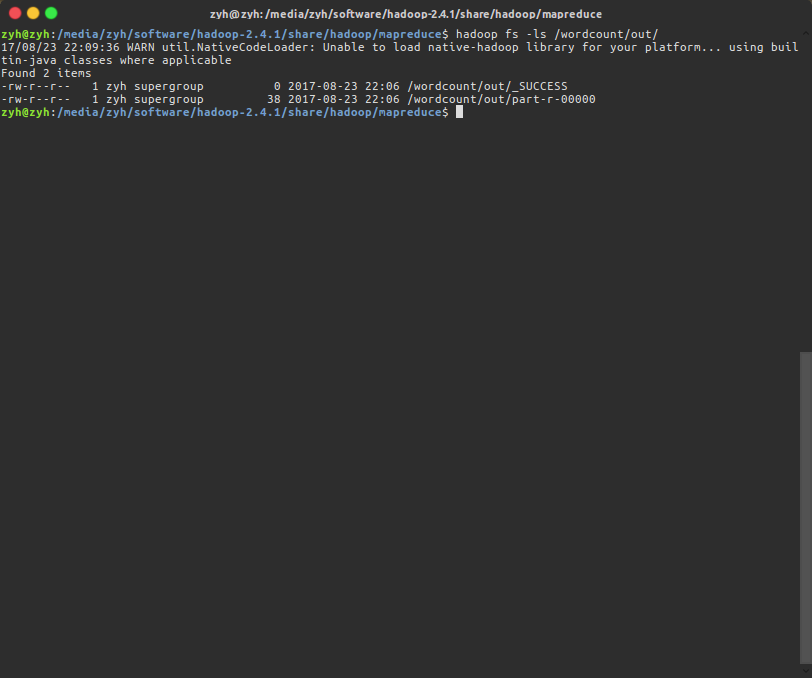
到/wordcount/out查看MR分析结果,并使用命令下载文件
$ hadoop fs -ls /wordcount/out/
$ hadoop fs -get /wordcount/out part-r-00000
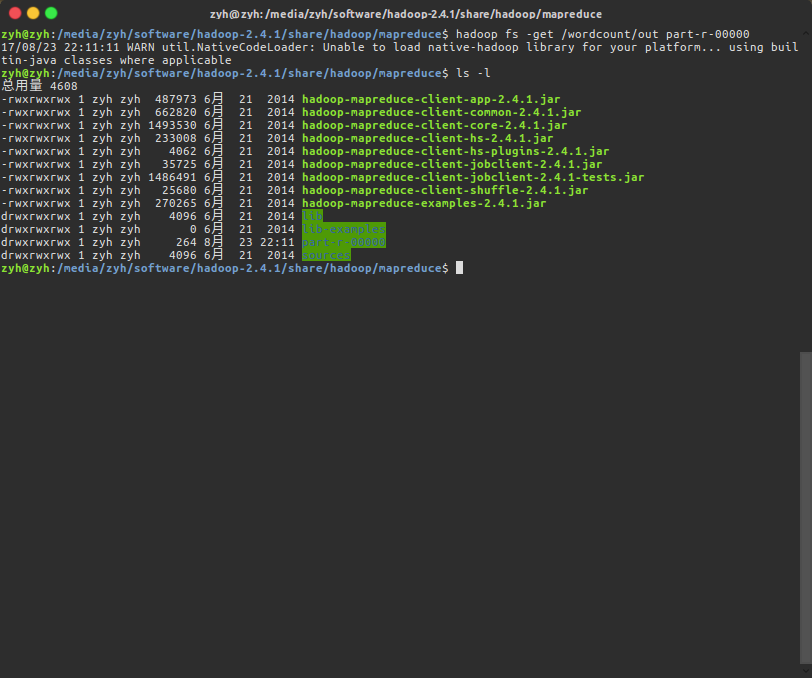
查看MR分析结果