初识MapReduce
mapredice其实就是分而治之的一种思想,hadoop的mapreduce是应对大数据产生的一种计算方式。分为两个步骤,maptask和reducetask。多个maptask并发执行运算输入数据,每个maptask各司其职,各自为政。多个reducetask并发执行,但它依赖于maptask,它输入参数是maptask的输出参数。
mapreduce框架中角色
核心角色有三个,分别为maptask,reducetask,mrappmaster,他们都是在进行运算过程中生成的进程。
- mrappmaster 协调maptask和reducetask的工作
- maptask 对数据进行第一阶段运算
- reducetask 对maptask输出的数据进行第二阶段运算
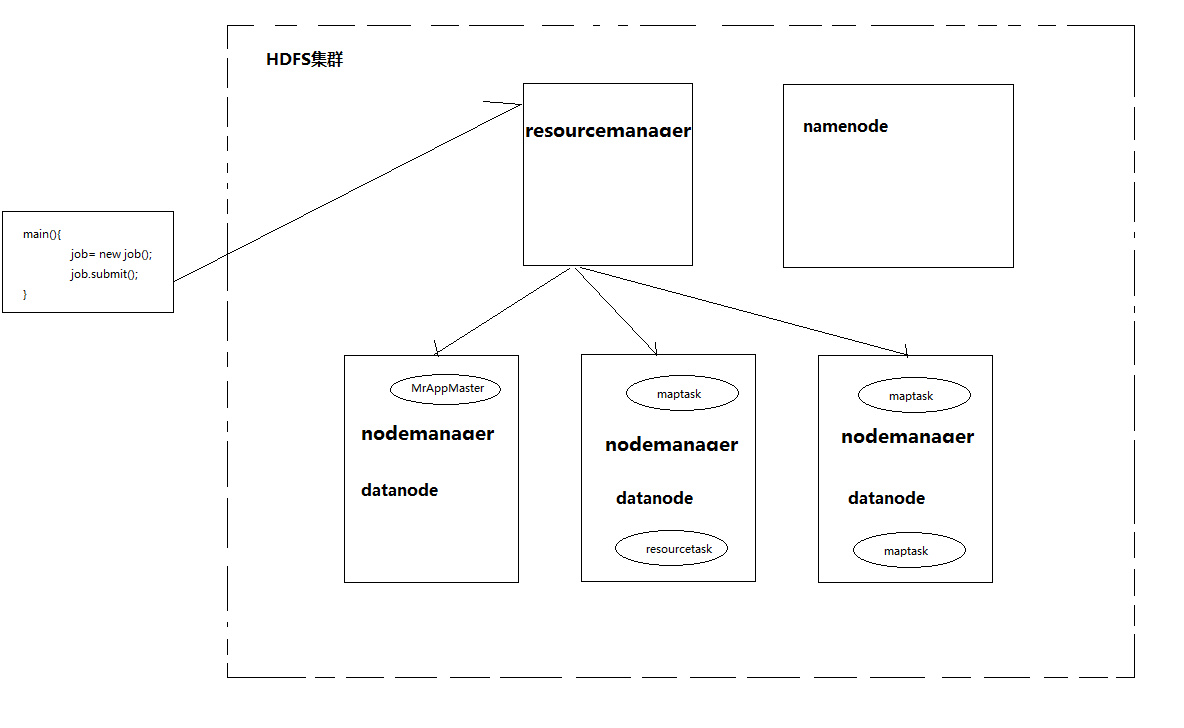
运行流程
当mapreduce主程序启动后会生成yarnRunner Proxy代理
根据用户指定的文件、相关blocksize配置,生成切片,封装成job.split,除此之外生成job.xml参数,wordcount.jar等信息
将生成的数据一同发送给yarn
yarn收到信息以后,会在resourcemanager维护的队列中初始化task
namenode发现队列中的task,会在自己内存中生成mrappmaster进程,mrappmaster的主要职责是协调好maptask及reducetask的运行。
mrappmaster会根据job.split文件中的切片信息向resourcemanager申请生成指定个数的maptask任务。
maptask启动以后会调用InputFormat组件,根据切片的描述信息,到hdfs上下载对应block块,将块的数据作为数据源进行map运算。
待maptask程序运行完成以后,mrappmaster进程向resourcemanager申请启动reducetask
yarn收到信息以后,会在resourcemanager维护的队列中初始化task
nodemanager发现队列中的task,为reducetask分配cpu以及内存,运行reducetask。
reducetask对maptask生成的数据进行汇总处理,并将结果上传到hdfs目录中。要注意的是生成maptask、resourcetask的资源分配这个过程需要resourcemanager统一管理.