MapReduce切片规划源码剖析
切片规划最终会形成一个文件job.split。里面存放这切片信息,首先要明确一点是maptask的数量于切片的数量有直接对应关系。mrappmaster在启动maptask时,会去job.split文件中找切片信息,有几个切片就启动几个maptask,每个切片分配一个maptask并行实例。我们通过追源码,找到了这个文件。
MapReduce框架会把它存在我们本机的某个路径。它是MapReduce对于待处理数据的一个描述信息文件。
关于切片需要注意的几点:
- 文件是怎么进行切分的?
- 切片的大小是怎么控制的?
源码追踪
根据源码追踪,发现切片的划分是在FileInputFormat的getSplits()方法中完成的。getSplits的大致业务逻辑可分为下列几个阶段
- 根据配置文件拿到切片大小,源码Math.max(minSize, Math.min(maxSize, blockSize));(如果我们没有设置过mapreduce.input.fileinputformat.split.minsize,mapreduce.input.fileinputformat.split.maxsize,那么默认的切片大小为128M,及为hdfs中block块大小)
- 根据不同的文件系统,获取文件规划的上传目录。(hdfs-> hdfs://…../.staging/jobid或file->file://…../.staging/jobid)
- 根据用户指定的hdfs目录找到对应的所有文件
- 遍历所有文件,拿到文件的元数据,对每个文件进行切片规划
- 规划的一个策略:根据拿到的切片大小来切每个文件,假如文件大小为300M,切片大小为128M,那么走完循环后文件会被分为3块(0-128,128-256,256-300)
- 将切片封装为job.split
- 生成其他信息,比如job.xml(所有的参数信息)。
- 将生成的所有文件以流的形式写到指定上传目录,也就是hdfs://…./.staging/jobid
一步一步断点调试,通过本地运行MapReduce程序,进入debug。先在job.waitForCompletion(true);打断点。
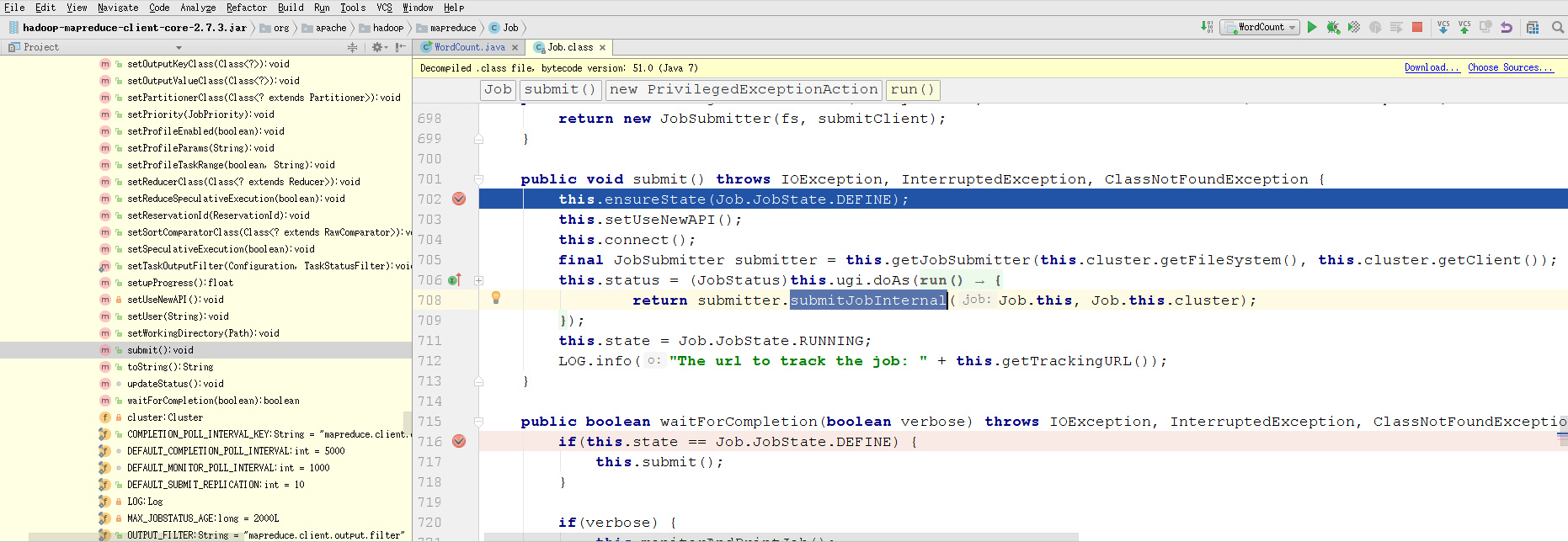
发现会进入submitter.submitJobInternal(),跳进去
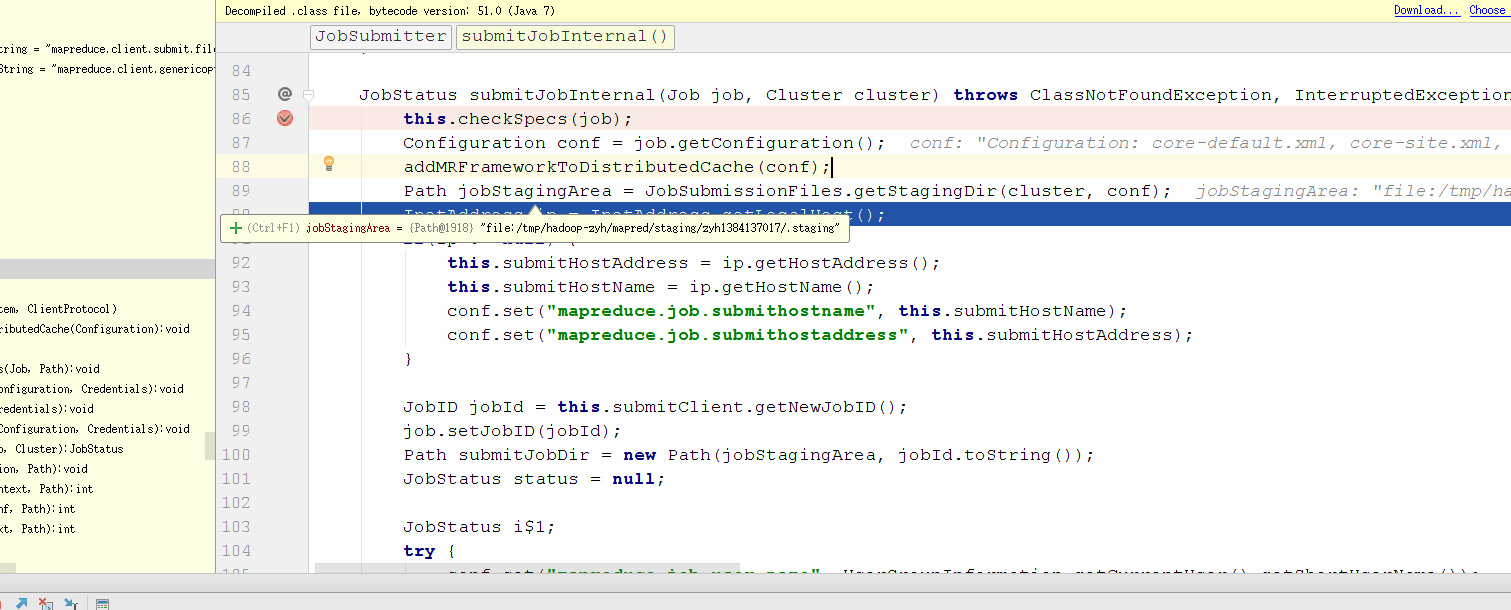
可以看到拿到了jobStagingArea,后续拿到了jobId,最后拼成了submitJobDir。这个目录就是上面提到的job.split存放的目录。
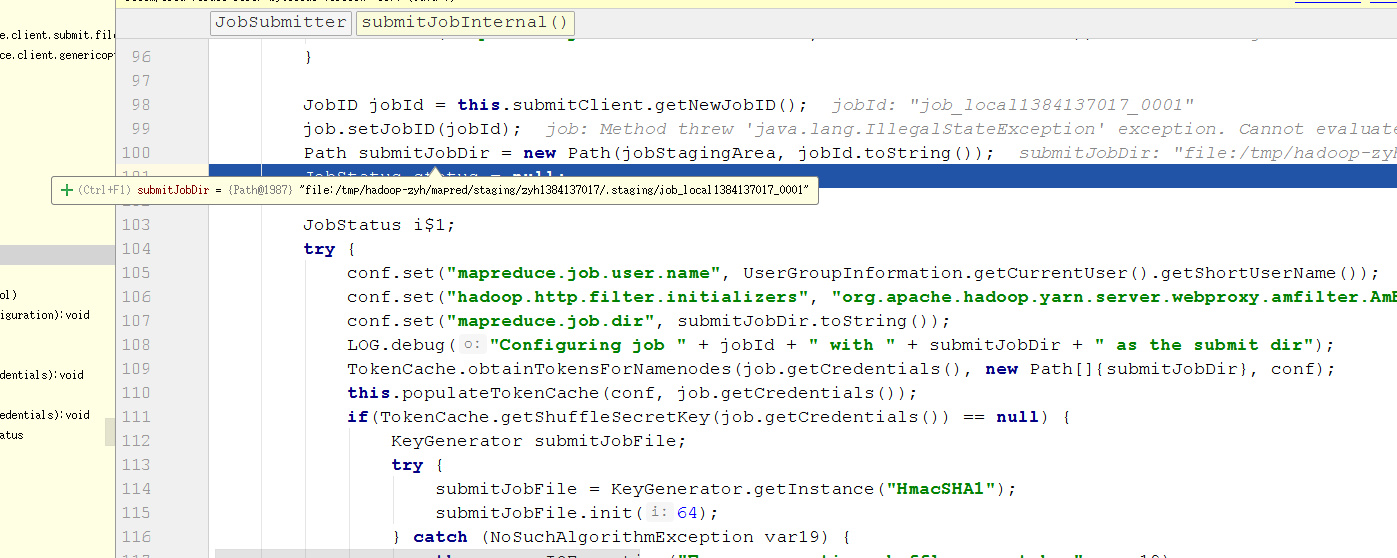
拿到submitJobDir以后,MapReduce开始调用this.writeSplits(job, submitJobDir)对文件进行逻辑切分,形成job.split文件(后续详细解析里面的内部详情)
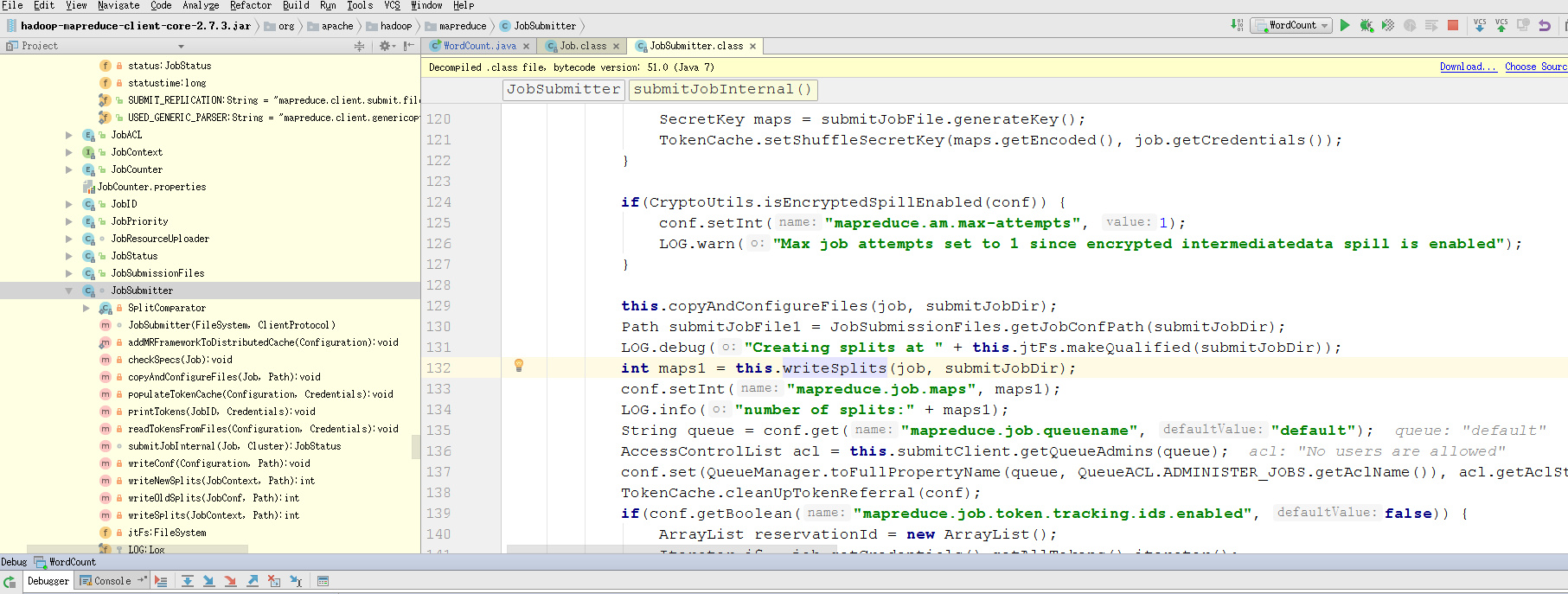
后续获取配置信息。形成job.xml文件,这个文件里面定义了hadoop中各种各样的配置信息
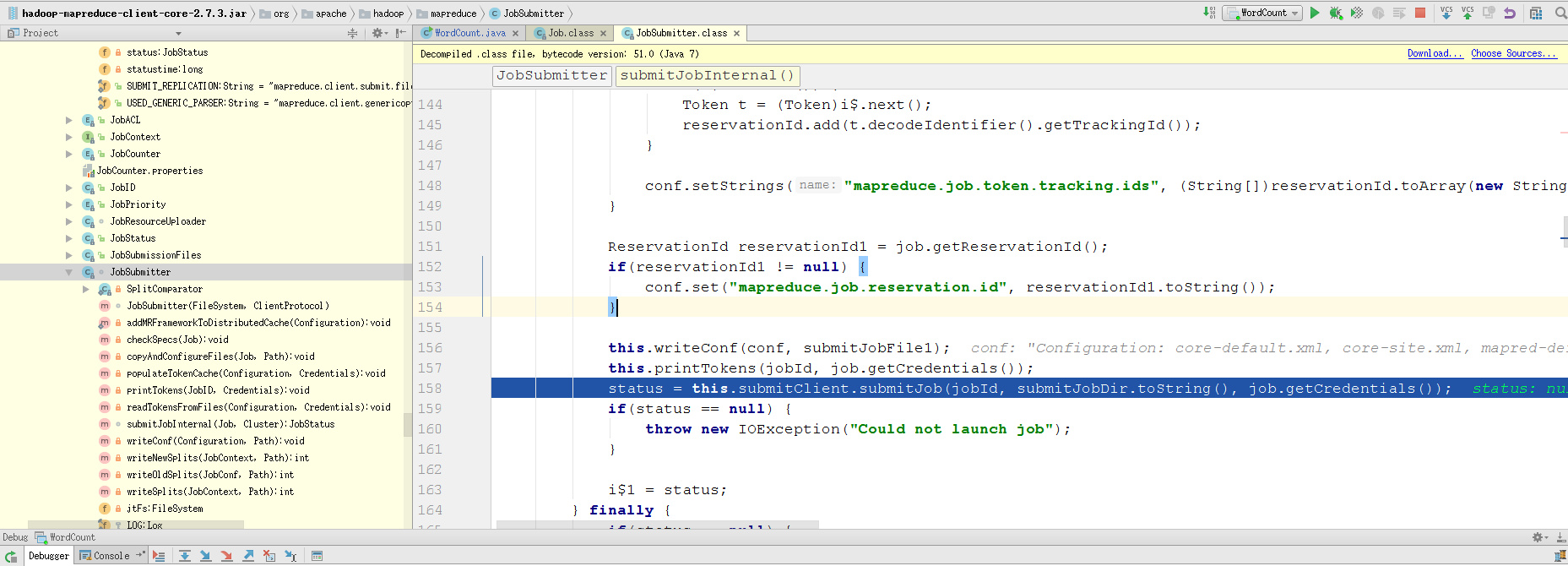
最后将job.split,job.xml,写到对应的submitJobDir目录下。
深入writeSplits逻辑
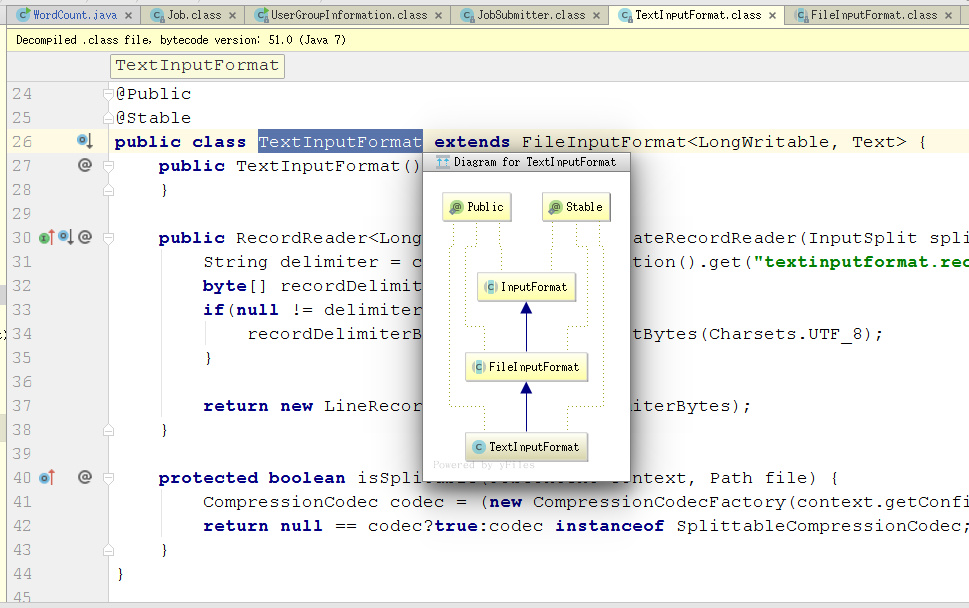
在this.writeSplites()我们如何跳到具体方法中,我们直接ctrl+左键点进取以后会发现是一个抽象类InputFormat。
是这样如果你在初始化job是没有指定用哪个inputFormat,那么mapreduce框架默认会使用TextInputFormat
使用快捷键ctrl+shift+T搜索TextInputFormat,我们会发现找不到getSplits方法,这是因为方法在父类里面,进去父类FileInputFormat中就可以找到了,在第一行打断点运行就可以跳进去了。
InputFormat的类结构图
来看看getSplits方法的具体逻辑,我直接把源码粘过来了,我在关键的地方加了注释
1 | |
切片的计算方式
首先会计算出minSize,默认1
long minSize = Math.max(this.getFormatMinSplitSize(), getMinSplitSize(job));
1 | |
计算maxSize,默认128M
long maxSize = getMaxSplitSize(job);
1 | |
最后计算splitSize
long splitSize = this.computeSplitSize(blockSize1, minSize, maxSize);
1 | |
在切文件是采用这样的判断方式
(double)bytesRemaining / (double)splitSize > 1.1D
只要文件的大小/splitSize > 1.1倍时就会对文件进行切分
问题总结
归结一点就是mapreduce主程序运行后,会将每个文件进行逻辑切分,这里的逻辑切分的意思就是说并非真的对文件进行切分,只是生成一些描述信息,存到job.split文件中。
有几个切片就会生成几个maptask。maptask数量和切片的数量一一对应,因为yarnRunner会把job.split发给yarn,yarn收到这个文件以后会读取里面的切片信息,然后初始化maptask。
文件切分的方法是InputFormat类提供的,在getSplits方法中我们可以看到(double)bytesRemaining / (double)splitSize > 1.1D,只要文件的大小/splitSize > 1.1倍时就会对文件进行切分,splitSize默认是128M。
通过查看源码我们可以知道通过两个参数mapreduce.input.fileinputformat.split.minsize和mapreduce.input.fileinputformat.split.maxsize就可以调节。
了解了切片后,我们到底切多大?是比HDFS block大好还是比他小好?为什么要对文件进行切分?要明白切片规划的其中一个重要的原因就是mapreduce期望,在运行每个maptask时,任务所需要的输入数据恰好能在本地,这样就能保证每次maptask于hdfs的数据交互时,直接可以从本地拿到数据。理想状态(切片的大小=blocksize,减少maptask于hdfs的跨网络数据传输)。
本人水平有限,不当之处希望各位高手指正。邮箱cnnqjban521@gmail.com。