MapReduce的Shuffle机制
在编写MapReduce,启动主程序以后,到底maptask和reducetask之间是怎么工作的?数据是如何进行排序的?
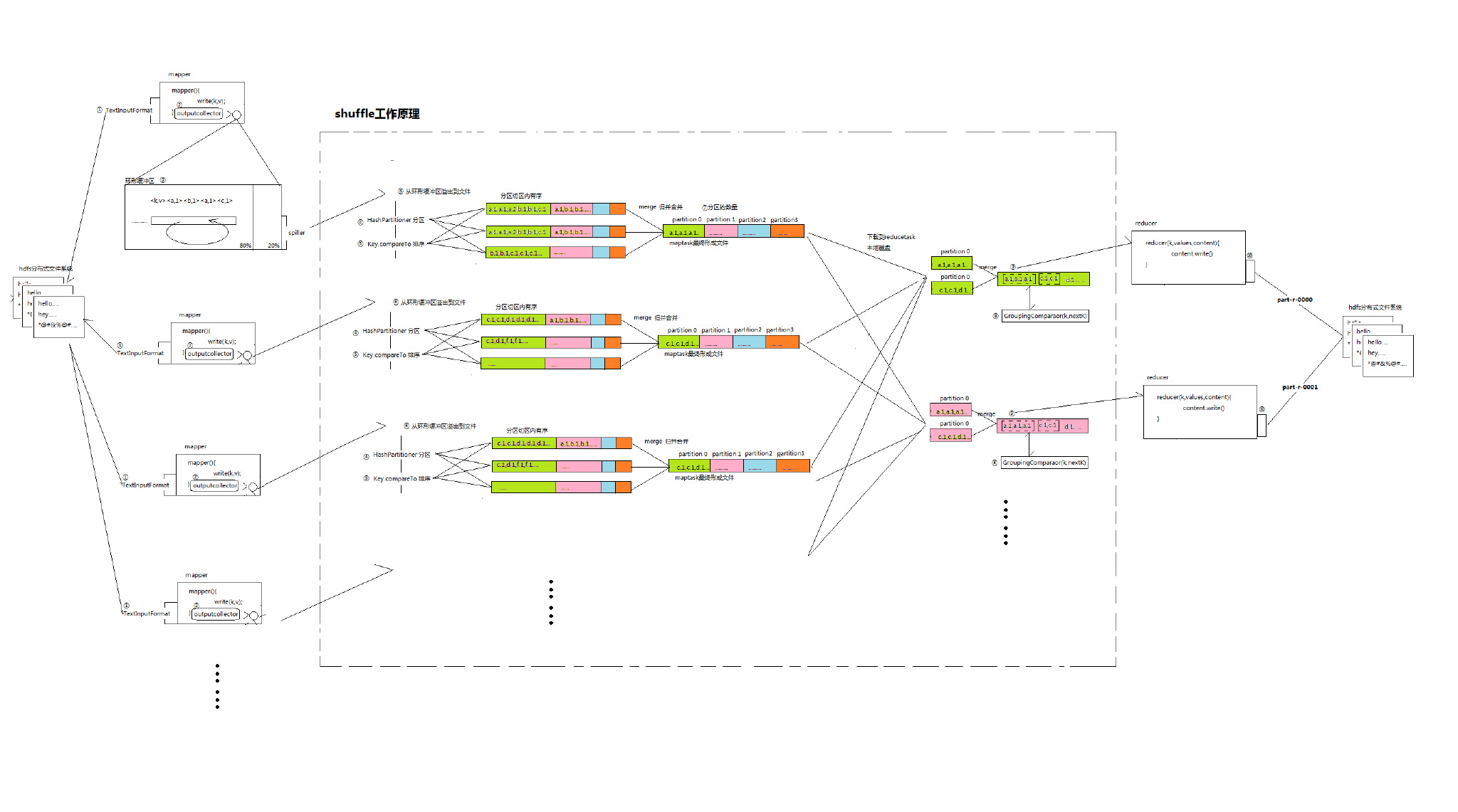
1.inputFormat:我们知道mapreduce主程序初始化job以后会对输入的数据进行切片规划,生成job.split文件,inputFormat会读取job.split文件,根据信息从DHFS中找到要读取的数据,调用recordReader将数据读成一行,传入mapper中,默认的使用的是TextInputFormat
2.当我们在mapper调用write后,outputCollector会将输出的数据写入环形缓冲区中
3.环形缓冲器的大小默认为100M,当环形缓冲区的内容达到自身容量的80%后,进行溢出操作,生成多个文件。期间会经过4、5、6这几个操作
4.我们可以在该类中定义要分几个区,例如hashCode % reduceTask,这样我们可以使用job.setNumReduceTask动态划分分区大小
5.对分区中的序列进行排序。同样排序的方式可以根据不同的业务做调整
6.溢出这个操作是由一个叫做spiller的组件完成的,当缓存区数据达到制定标准后进行溢出到文件操作。
8.GroupingComparaor组件,它可以对reducetask最终形成的文件的内容进行分组。
在WordCount的mapper程序中,输出write(word,1)
经过shuffle处理后的数据就是一个经过分组后的有序数据。
reducetask的reduce(k,values)会读的就是每一组的数据。
GroupingComparaor组件的逻辑会将文件内容分成三个组,第一组<a,1><a,1><a,1>。第二组<c,1><c,1>…
那么这就意味着,reducetask第一次reduce的k为a,values为1,1,1;第二次reduce的k为c,values为1,1。
9.将分组后的数据按组分批次发给reducetask的reduce方法。
10.write以后OutputFormat组件会调用RecordWriter,将内容上传到hdfs中。
本人水平有限,不当之处希望各位高手指正。另外插入是在画图中画的,看起来不精致请见谅。