搭建基于Hadoop的Hive数据仓库
Hive是基于Hadoop的一个数据仓库,我们可以将结构化的数据映射为一张数据库表,为此提供类似与SQL的HQL来查询数据。使用Hive可以提高我们的开发效率,缩短开发周期,最重要的是它降低了编写MapReduce编写的难度,可能在应对很复杂的mapReduce程序时,我们只需要写一条简单的sql就可以实现具体功能了。
安装
我们可以从Hive的官网https://hive.apache.org/下载对应的安装包。
这里我使用的版本是1.2.1。
1.修改配置文件
$ cp hive-env.sh.template hive-env.sh
在末尾加上下面语句,配置好环境变量
1 | |
创建 conf/hive-site.xml文件
$ cd conf;touch hive-site.xml
在里面指定要链接的数据库,javax.jdo.option.ConnectionURL参数用于指定我们存放数据元的地方
1 | |
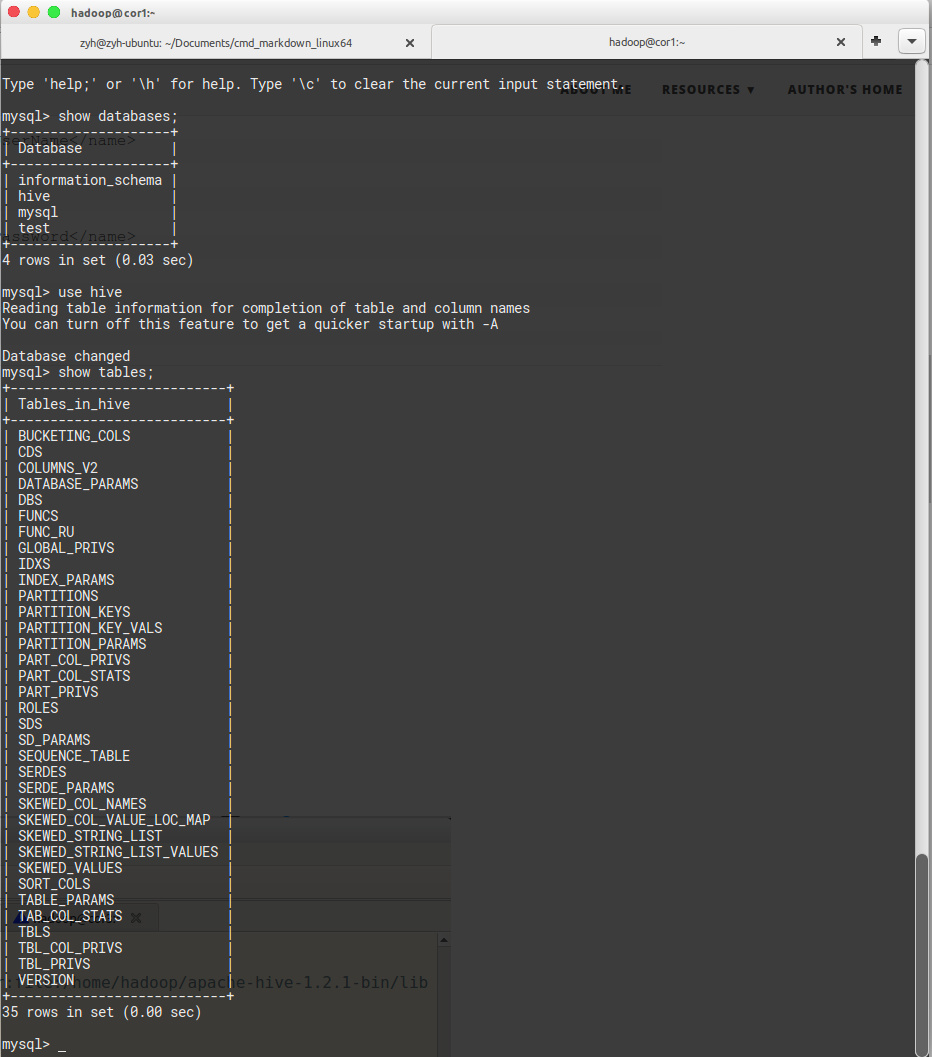
什么是元数据?元数据就是可以理解为描述数据的数据,这边写的是本机的mysql,这些描述数据的数据会存在mysql的hive库中,你可以在启动hive以后查看一下mysql数据这些数据到底长什么样子。
拷贝hadoop目录下配置文件到当前目录
$ cp $HADOOP_HOME/etc/hadoop/core-site.xml .
$ cp $HADOOP_HOME/etc/hadoop/hdfs-site.xml .
2.启动Hive
下面两种方法都可以启动
$ cd apache-hive-1.2.1-bin ; bin/hive
或者
$ hive –service hiveserver2 –hiveconf hive.server2.thrift.port=10000 –hiveconf hive.root.logger=INFO,console
$ bin/beeline -u jdbc:hive2://cor1:10000 -n hadoop
我使用的是第一种方法
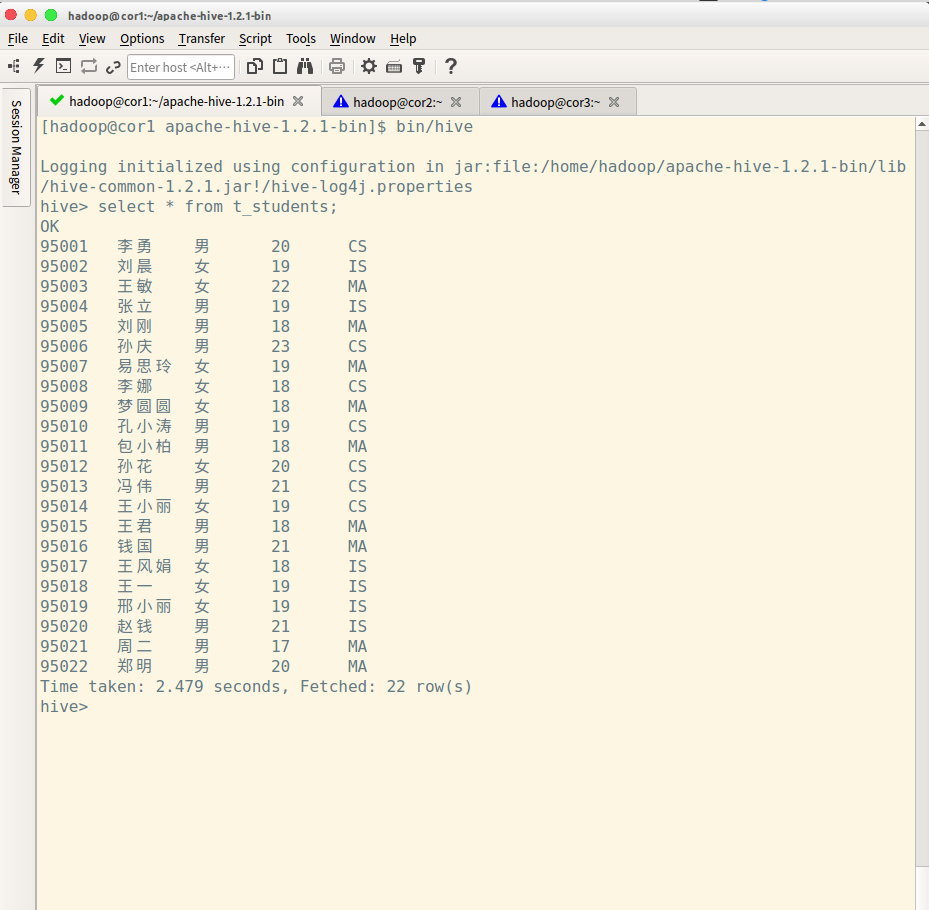
Hive一些简单操作
下面是一些简单的操作。
1.创建外部表
create external table extertable(id string,name string) row format delimited fields terminated by ‘,’;
2.插入数据
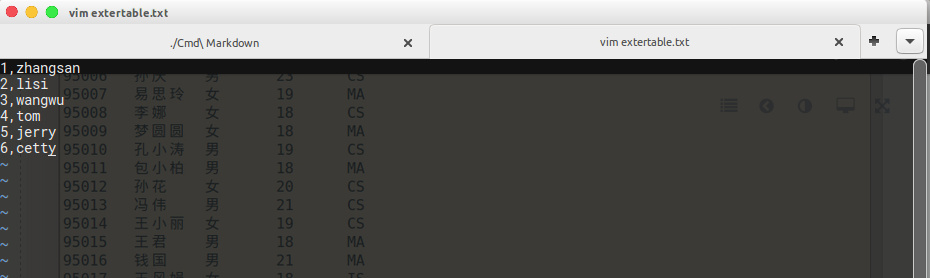
现在本地生成一个文本extertable.txt,在里面输入下面内容
1 | |
使用下面命令就可以将数据导入到表中
load data local inpath ‘xxxx/xxxx/extertable.txt’ into table extertable;
3.查询
select * from extertable;
Hive分桶
其实Hive的本质还是在帮助我们运行MapReduce,它会将HQL按模板转化成指定MapReduce代码。这里说一下Hive分桶的概念,那么什么是分桶,为什么会用分桶。我们知道在运行MapReduce程序时,可以指定多个Reduce Task来处理不同partition的数据,Hive的分桶就可以很好的实现这个功能,将不同的reduce task 生成的数据导入到不同的文件中。
我们可以使用下面的语句来创建一个带分桶的表,值得注意的是,在使用分桶表时,错误的做法是直接往表里insert数据,这是不对的。正确的思路是,从其他的表中查询出数据,然后插入到该表中。
create table student(id int, age int,name string) partitioned by (stat_data string) clustered by (id) sorted by (age) into 2 buckets row format delimited fields terminated by ‘,’;
那么分桶后有什么好处呢?
最大的好处应该是提高join的效率。
数据经过分区,排序后,相同的id会被放在同一个桶内,这时再做链接查询时,就不会遍历全表。
Hive 自定义函数
Hive为我们提供了很多内置函数。除此之外还提供了自定义的接口,说其中一种实现套路继承UDF
1. 继承UDF,并重载evaluate方法
1 | |
2.打成jar包上传到服务器
这边推荐使用Eclipse打包成jar,我使用IDEA打包好久,比较麻烦。。
3.将jar包添加到hive的classpath
add JAR /home/hadoop/udf.jar;
4.4、 创建临时函数与开发好的java class关联
create temporary function toprovince as ‘cn.itcast.bigdata.udf.ToProvince’;