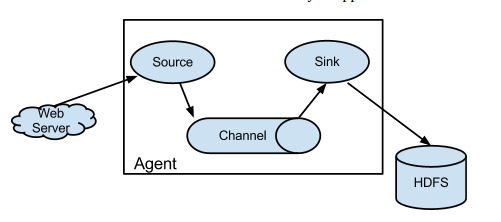
flume 是cloudera提供的一个高可靠、高可用、分布式的日志采集、聚合和传输的工具,flume最大的特点就是可以方便的定义各种sources(从哪收)和sinks(放在哪),来适应我们不同的业务场景。
使用
进入flume的目录,修改conf下的flume-env.sh,在里面配置JAVA_HOME
1. 从网络端口接收数据,下沉到logger
在flume的conf目录下新建一个文件,将下面内容写进去
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| # Name the components on this agent
#给那三个组件取个名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
#类型, 从网络端口接收数据,在本机启动, 所以localhost, type=spoolDir采集目录源,目录里有就采
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
#下沉的时候是一批一批的, 下沉的时候是一个个eventChannel参数解释:
#capacity:默认该通道中最大的可以存储的event数量
#trasactionCapacity:每次最大可以从source中拿到或者送到sink中的event数量
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
|
启动命令: 告诉flum启动一个agent,指定配置参数, –name:agent的名字
$ bin/flume-ng agent –conf conf –conf-file conf/netcat-logger.conf –name a1 -Dflume.root.logger=INFO,console
2. 监视文件夹
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| #
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
#监听目录,spoolDir指定目录, fileHeader要不要给文件夹前坠名
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /home/hadoop/flumespool
a1.sources.r1.fileHeader = true
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
|
启动命令:
$ bin/flume-ng agent -c ./conf -f ./conf/spool-logger.conf -n a1 -Dflume.root.logger=INFO,console
注:测试: 往/home/hadoop/flumeSpool放文件(mv ././xxxFile /home/hadoop/flumeSpool),但是不要在里面生成文件
3.用tail命令获取数据,下沉到hdfs
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| #
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/log/test.log
a1.sources.r1.channels = c1
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = events-
# 每个10分钟重新生成一个新的时间目录
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
# 文件的滚动周期(秒)
a1.sinks.k1.hdfs.rollInterval = 3
# 文件大小滚动(bytes)
a1.sinks.k1.hdfs.rollSize = 20
# 写入多少个event后滚动,事件个数
a1.sinks.k1.hdfs.rollCount = 5
a1.sinks.k1.hdfs.batchSize = 1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
|
启动命令:
bin/flume-ng agent -c conf -f conf/tail-hdfs.conf -n a1
4. 多个agent串联
agent1配置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 4141
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
|
启动:
$ bin/flume-ng agent –conf conf –conf-file conf/avro-hdfs.conf –name a1 -Dflume.root.logger=DEBUG,console
agent2配置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| #
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/log/test.log
a1.sources.r1.channels = c1
# Describe the sink
a1.sinks = k1
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = hadoop01
a1.sinks.k1.port = 4141
a1.sinks.k1.batch-size = 2
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
|
启动命令:
$ bin/flume-ng agent –conf conf –conf-file conf/tail-avro-avro-logger.conf –name a1 -Dflume.root.logger=DEBUG,console