散列表冲突解决策略
选择一个”好”的散列函数可以在一定程度上减少冲突,但在实际应用中,很难完全避免发生冲突,所以选择一个有效的处理冲突的方法是散列法的另一个关键问题。创建散列表和查找散列表都会遇到冲突。两种情况下处理冲突的方法应该一致。下面以创建散列表为例,来说明处理冲突的方法。
处理冲突的方法可分为两类:开放地址法和链地址法
开放地址法
核心原理:把记录都存在散列表数组中,当某一记录关键字key的初始散列地址$$H_0=H(key)$$发生冲突时,以$$H_0$$为基础,采取合适方法计算得到另一个地址$$H_1$$,如果$$H_1$$仍然发生冲,以$$H_1$$为基础在求一下地址$$H_2$$,若$$H_2$$仍然冲突,在求$$H_3$$以此类推。直到$$H_k$$不发生冲突为止,则$$H_k$$为该记录在表中的散列地址。
这种方法在寻找“下一个”空的散列地址时,原来的数组空间对所有的元素都是开放的。所以称为开放地址法。通常把寻找“下一个”空位的过程叫做探测,上述方法可用如下公式表示:
$$H_i=(H(key)+d_i)%m\quad i=1,2,\cdots,k(k\leq m - 1)$$
(1)线性探测法
$$d_i=1,2,\cdots,m-1$$
这种探测方法可以将散列表假想成一个循环表,发生冲突时,从冲突地址的下一个单元顺序寻找空单元,如果到最后一个位置也没找到空单元,则回到表头开始继续查找。直到找到一个空位。就把此元素放在此空位。如果找不到空位,则说明散列表已满,需要进行溢出处理。
(2)二次探测法
$$d_i=1^2,-1^2,2^2,-2^2,3^2,\cdots,+k^2,-k^2(k\leq\frac{m}{2})$$
结合着线性探测法来说,冲突时,先往右边找,如果依然冲突就从左边开始找。
(3)伪随机探测法
冲突时,$$加一个随机数再进行模运算
例如,散列表的长度为11,散列函数$$H(key)=key%11$$,假设表中已填有关键字分别为17、60、29的记录。下图,现有四个记录,其关键字为38,由散列函数得到散列地址为5,产生冲突。
若用线性探测法处理时,得到下一个地址6,仍然冲突,在求下一个地址7,还是冲突,知道散列地址为8的位置,完成探测
若用二次探测发,散列地址5冲突后,得到下一个地址6,还是冲突,再求的下一个地址是4,完成探测
若使用伪随机探测法,假设产生一的伪随机数为9,则计算下一个散列地址为$$(5+9)%11=3$$,由于脸很好,一次就完成探测。
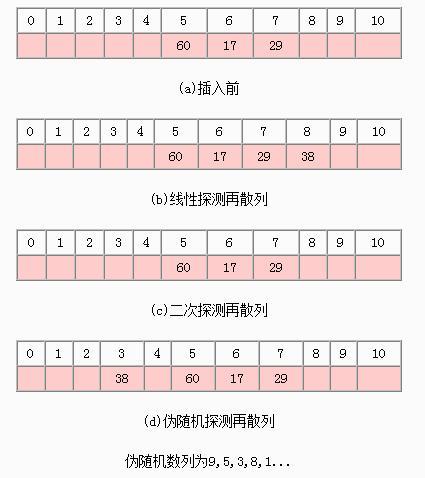
从上述线性探测法的处理过程中可以看到一个现象,当表中i,i+1,i+2位置上已填有记录时,下一个散列地址为i,i+1,i+2和i+3的记录都将填入i+3的位置,这种在处理冲突过程中发生的两个第一个散列地址不同的记录争夺同一个后继散列地址的现象称作二次聚集(或称为堆积),即在处理同义词的冲突过程中又添加非同义词冲突。
可以看出上述的三种方法各有优缺点,线性探测法的优点是:只要散列表未填满,总能找到一个不发生冲突的地址。缺点是:会产生二次聚集现象。二次探测法的优点:可以避免二次聚集。缺点也很明显:不能保证一定能找到不发生冲突的地址。
链地址法
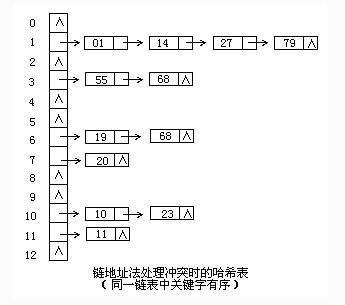
核心原理:把具有相同散列地址的记录放在同一个单链表中,称为同义词链表。有m个散列地址就有m个单链表,同时用数组$$HT[0\cdots m-1]$$存放各个链表的头指针,凡是散列表地址为i的记录都以结点方式插入到以$$HT[i]$$为头结点的单链表中。
例如 一组关键字为(68,1,14,10,23,27,79,19,20,11,55),设散列函数为$$H(key)=key%13$$,用链表处理后的结果如下图所示:
参考: Data Structure (2nd Edition)http://book.knowsky.com/book_1030305.htm