系统的方向为收集ngnix访问日志,做离线批处理统计分析,为上层决策提供数据支持
系统设计
小型集群(3台 CentOS),cor1/cor2/cor3
核心组件
下面对用到的核心组件做一个概述,心里有一个大概
FlumeNG : 主要收集WEB端产生的ngnix日志汇总到HDFS中
HDFS : 存放前一天汇总的数据,为后续离线分析做准备
MapReduce : 主要进行ETL,清洗,过滤,规整。根据HDFS汇总数据生成贴源表
Hive : 加载HDFS上的数据到仓库(加载贴源表),使用hive sql根据贴源表进一步计算出各维度指标
Sqoop : 同步Hive数据仓库中各维度指标到mysql数据库,或者redis。为WEB端展示提供基础数据
Azkaban : 各个组件的粘合剂,用来调度各自动脚本,实现自动化
搭建集群
1.开发阶段使用虚拟机,这边用的是VirtualBox.先准备3台CentOS虚拟机,cor1/cor2/cor3,这边不做详述
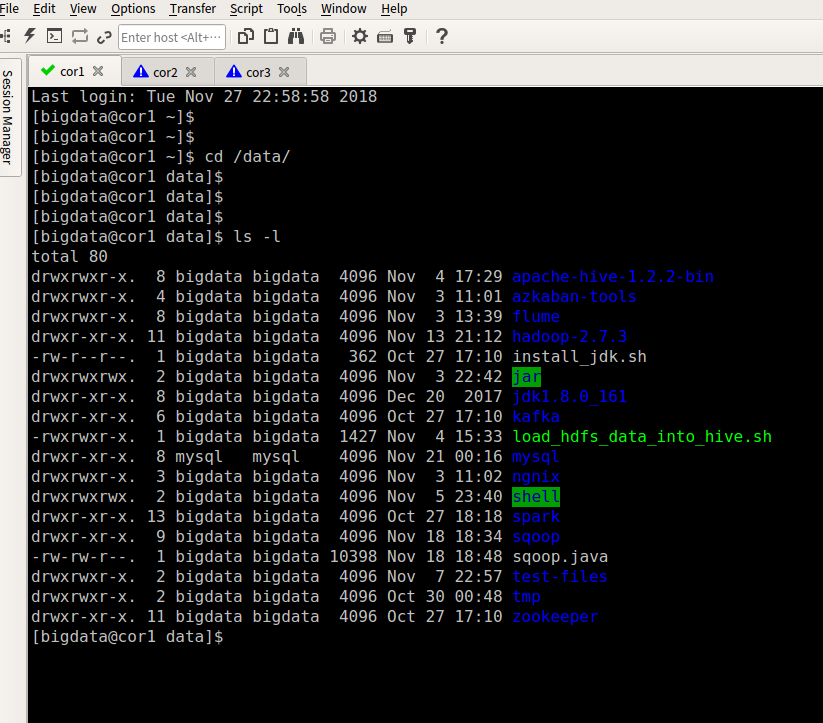
2.在cor1上部署hadoop,zookeeper,hive,flume,sqoop,mysql,azkaban,这边不做详述
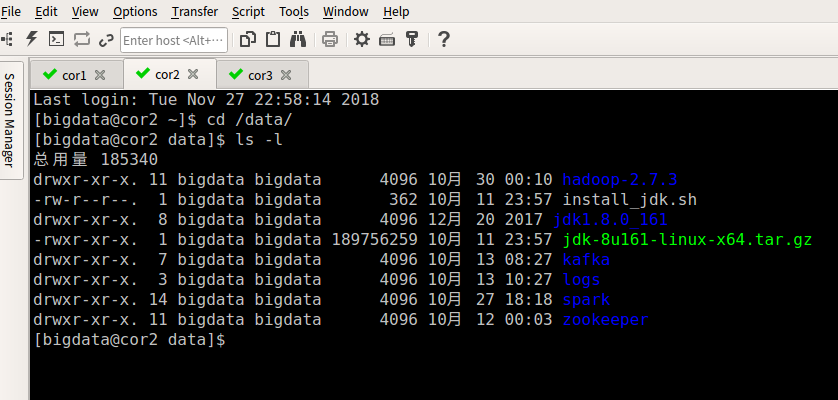
3.在cor2上部署hadoop,zookeeper,这边不做详述
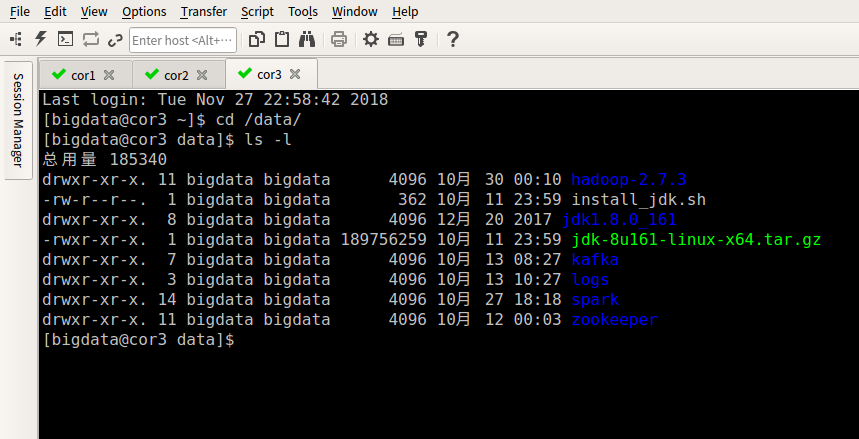
4.在cor3上部署hadoop,zookeeper,这边不做详述
收集数据
收集数据这边使用,flumeNG采集ngnix日志上传到HDFS,安装好flumeNG,在conf目录下创建tail-hdfs.conf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/log/test.log
a1.sources.r1.channels = c1
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollInterval = 3
a1.sinks.k1.hdfs.rollSize = 20
a1.sinks.k1.hdfs.rollCount = 5
a1.sinks.k1.hdfs.batchSize = 1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
|
启动FlumeNG:
1
2
| bin/flume-ng agent -c conf -f conf/tail-hdfs.conf -n a1
|
FlumeNG手册:http://flume.apache.org/FlumeUserGuide.html
当然你也可以不使用FlumeNG,使用shell脚本定时检测某个目录下所有的文件定时上传到HDFS中。下面提供一个参考脚本的写法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| #!/bin/bash
#
# Data Input: /data/weblog/preprocess/input
# Data Output: /data/weblog/preprocess/output
# Author: zyh
# ===========================================================================
#set java env
export JAVE_HOME=/data/jdk1.8.0_161
export JRE_HOME=${JAVE_HOME}/jre
export CLASS_PATH=${JAVE_HOME}/lib/dt.jar:${JAVE_HOME}/lib/tools.jar
export PATH=$PATH:${JAVE_HOME}/bin:${JRE_HOME}/bin
#set hadoop env
export HADDOP_HOME=/data/hadoop-2.7.3
export PATH=$PATH:${HADDOP_HOME}/bin:${HADDOP_HOME}/sbin
#flume采集生成的日志文件存放的目录
log_flume_dir=/data/flumedata/
#待上传文件存放的目录
log_pre_input=/data/weblog/preprocess/input
#获取时间信息
day_01=`date -d'-1 day' +%Y-%m-%d`
syear=`date --date=$day_01 +%Y`
smonth=`date --date=$day_01 +%m`
sday=`date --date=$day_01 +%d`
#读取日志文件的目录,判断是否有需要上传的文件
files=`hadoop fs -ls $log_flume_dir | grep $day_01 | wc -l`
if [ $files -gt 0 ]; then
hadoop fs -mv ${log_flume_dir}/${day_01} ${log_pre_input}
echo "success moved ${log_flume_dir}/${day_01} to ${log_pre_input} ....."
fi
|