CDH5.15.0升级spark1.6到2.3
CDH5.15.0安装集群以后,默认安装的spark是1.6版本。添加的时候没有spark2,因为spark1.6好多新功能都不能使用,所以这边对其进行升级。
安装包
- parcel、parcel.sha和manifest.json
- csd
下载parcel等文件点我下载
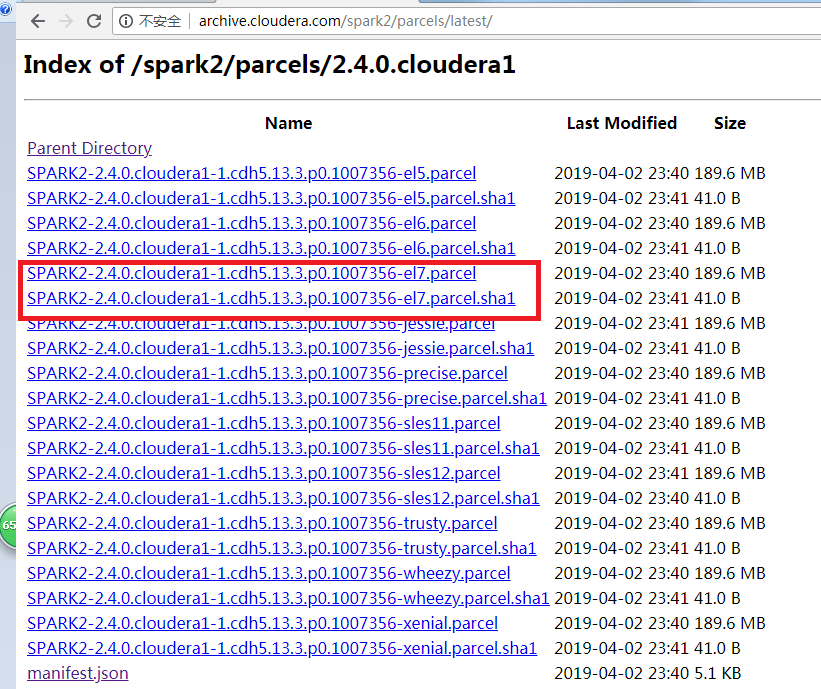
下载csd文件点我下载
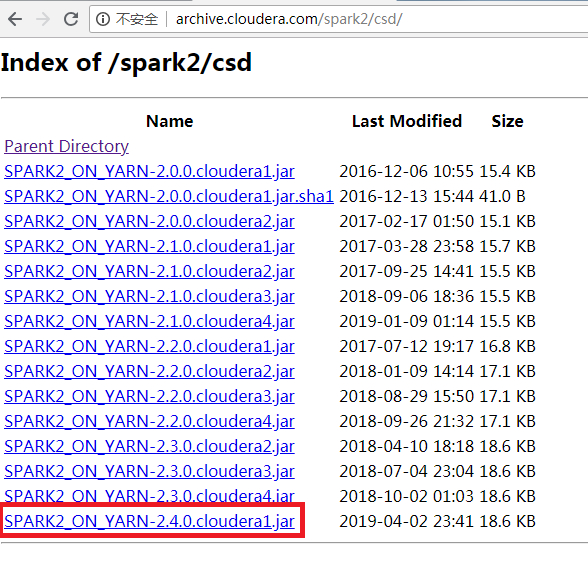
关于版本,csd和parcel的版本要对应上本例子中都是cloudera1;parcel的版本要选择适合自己操作系统的,本例中使用的是centos7,所以下载el7
下载好所有文件
1 | |
上传
将SPARK2_ON_YARN-2.4.0.cloudera1.jar上传到主节点的*/opt/cloudera/csd/*
没有目录的话创建一个
将其余文件上传到主节点的*/opt/cloudera/parcel-repo/*
目录下面如果有重名文件必须删掉,如果没有则不用管
重启CSM
1 | |
激活安装
到cloudera manager界面 主机-》parcel-》SPARK2 做激活
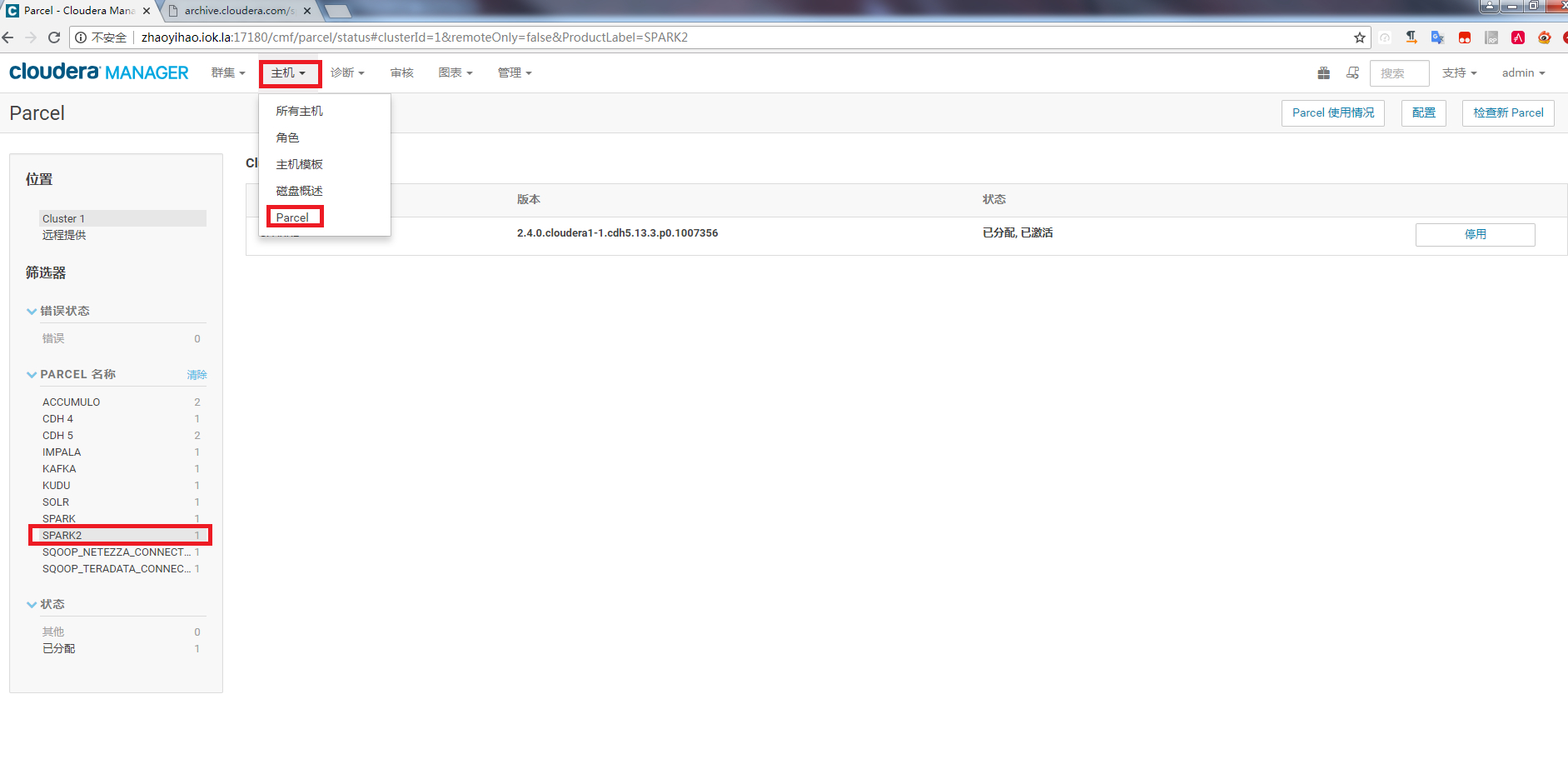
按照正常操作添加SPARK2到集群即可
验证
到node1节点下运行spark-shell发现报错
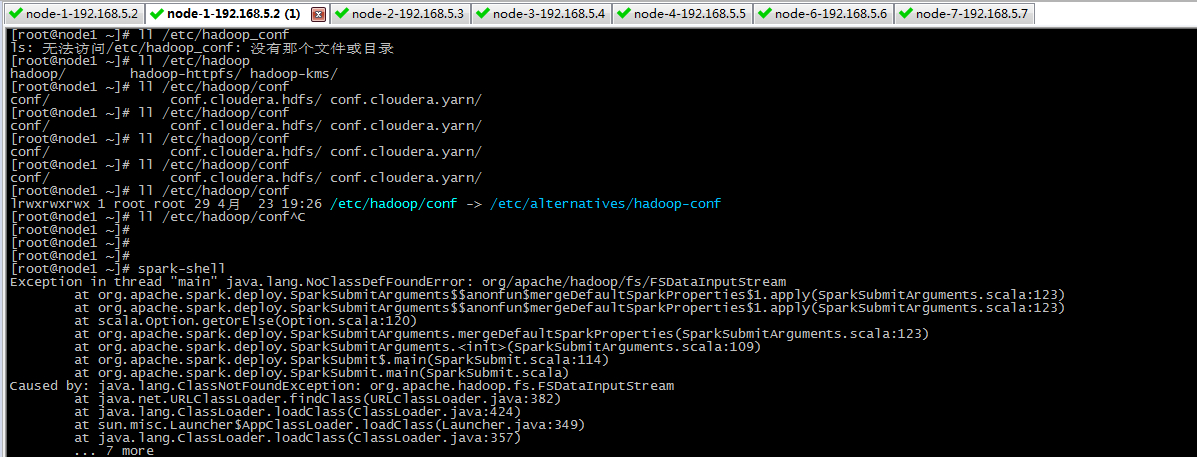
首先我们得知道下面这些事情
- CDH安装目录 /opt/cloudera/parcels/CDH/
- SPARK2安装目录 /opt/cloudera/parcels/SPARK2
- 所有配置文件目录为 /etc/
将CDH中spark配置文件拷贝到SPARK2的配置文件中,并配置spark-env.sh文件
1 | |
检查一下配置文件
1 | |
将Spark2加入到环境变量中
1 | |
spark on yarn测试
1 | |
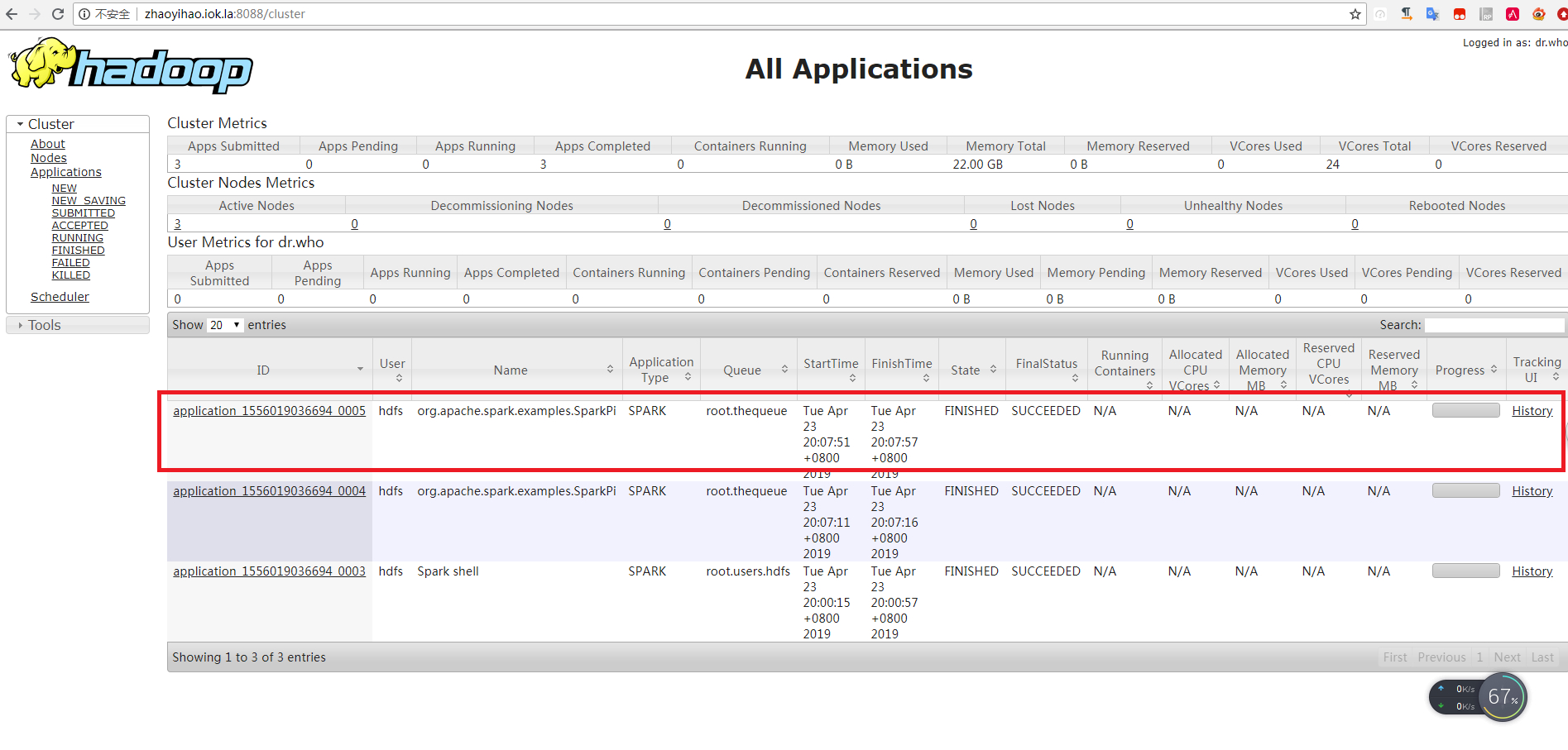
到yarn上查看任务http://zhaoyihao.iok.la:8088/cluster
Spark SQL 操作Hive测试
这里有一个参数特别重要spark.sql.warehouse.dir下面是官方解释
When working with Hive, one must instantiate SparkSession with Hive support, including connectivity to a persistent Hive metastore, support for Hive serdes, and Hive user-defined functions. Users who do not have an existing Hive deployment can still enable Hive support. When not configured by the hive-site.xml, the context automatically creates metastore_db in the current directory and creates a directory configured by spark.sql.warehouse.dir, which defaults to the directory spark-warehouse in the current directory that the Spark application is started. Note that the hive.metastore.warehouse.dir property in hive-site.xml is deprecated since Spark 2.0.0. Instead, use spark.sql.warehouse.dir to specify the default location of database in warehouse. You may need to grant write privilege to the user who starts the Spark application.
大概的意思是,使用hive需要sparksession设置支持选项,如果用户集群里,没有部署好的hive,sparksession也能够提供hive支持,在这种情况下,如果没有hive-site.xml文件,sparkcontext会自动在当前目录创建元数据db,并且会在spark.sql.warehouse.dir表示的位置创建一个目录,用户存放table数据,所以spark.sql.warehouse.dir是一个用户存放hive table文件的一个目录,因为是一个目录地址,难免会收到操作系统的影响,因为不同的文件系统的前缀是不一样了,为了适配性,spark鼓励在code中设置该选项,而不是在hive-site.xml中设置该选项。
1.如果没有部署好的hive,spark确实是会使用内置的hive,但是spark会将所有的元信息都放到spark_home/bin 目录下,也就是为什么配置了spark.sql.warehouse.dir 却不起作用的原因。而且,就算部署了hive,也需要让spark识别hive,否则spark,还是会使用spark默认的hive
2.只有在部署好的hive情况下,使用spark.sql.warehouse.dir才会生效,而且spark会默认覆盖hive的配置项。
下面摘自官方文档
Configuration of Hive is done by placing your hive-site.xml, core-site.xml (for security configuration), and hdfs-site.xml (for HDFS configuration) file in conf/. http://spark.apache.org/docs/latest/sql-data-sources-hive-tables.html
到cloudera manager 下载hvie的客户端配置,将hive-site.xml,core-site.xml,hdfs-site.xml复制到*/opt/cloudera/parcels/SPARK2-2.4.0.cloudera1-1.cdh5.13.3.p0.1007356/lib/spark2/conf*目录下
1 | |
进入spark-shell
1 | |