分布式缓存小结
缓存是提高服务访问速度的最有效的途径之一,下面对缓存的基本原理以及使用做一个小结。
缓存的基本原理
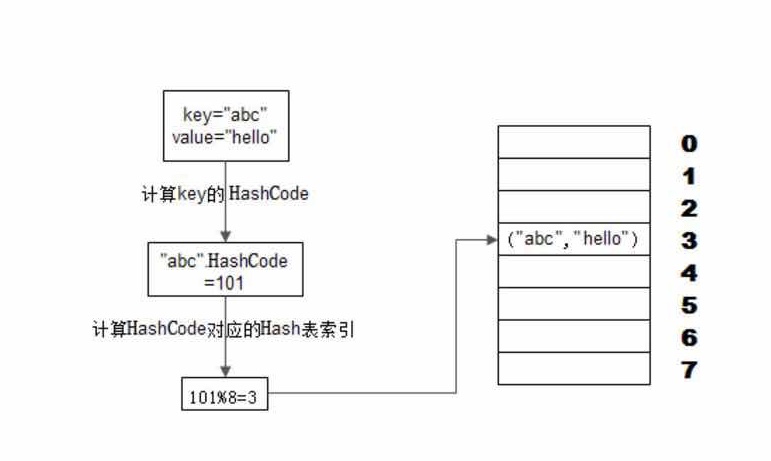
缓存指将数据存储在相对较高访问速度的存储介质中,以供系统处理;缓存的本质是一个内存Hash表,数据缓存是以KV形式存储在内存的Hash表中,Hash表数据读写的时间复杂度为O(1),可以参考下图加深理解,图片摘自-《大型网站技术架构:核心原理与案例分析》
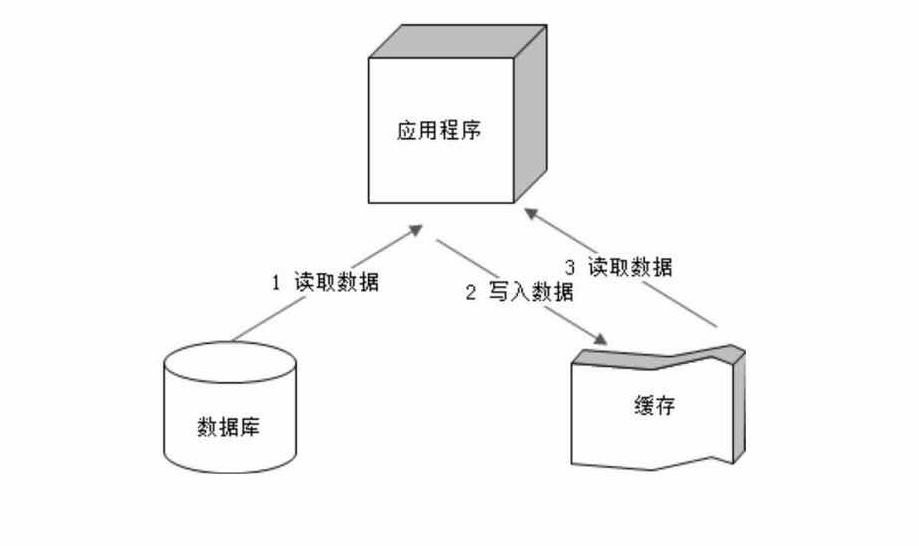
下图为是应用到代码中时的逻辑图
合理使用缓存
缓存虽然有很多好处,但是不合理的使用缓存反而会帮倒忙,成为系统累赘。作为一个合格的开发者,有必要搞清楚其应用点,以及在应用时的注意事项,下面对其进行简单小结。
- 频繁修改的数据
频繁修改的数据不宜存入缓存,如果你这么做了,数据在存入缓存后,应用还来不及访问,就已经再次失效了,途增系统负担。
- 没有热点访问的数据
内存往往是有限的,在往内存存储时,若 redis 检测到已经没有足够空间再容纳新增加数据时,会将长期未使用的数据清理出缓存。试想一下缓存被大量非热点数据,会是怎么样的?可能数据还没有再次被访问就已经被挤出缓存。在为数据做缓存时要遵守二八原则,大部分访问的数据没有集中在小部分数据上,那么缓存就没有意义了。
- 数据的不一致性和脏读
我们会见到某购物平台店家修改了商品,但前台并未实时更新数据,这种现象称为数据的不一致和脏读。缓存内会给数据设置过期时间,当数据过期后会重新加载数据库数据到缓存,所以往往会有一定延时。在互联网行业中,这种延时是可以被接受的。但假如产品人员表示非要优化,那么也有应对方案,就是做实时更新同步缓存,但这种做法会带来更多的系统开销和数据一致性问题。
- 缓存的高可用
在公司中,可能会发现对于业务场景,单台 redis 缓存服务即可满足日常需要。但随着业务不断扩展,可能就会带来很多问题。比如当 redis 服务宕机时,整个服务器的业务压力会落在数据库服务器上。这种压力的突然飙升很有可能造成服务宕机,而且这种宕机并不是简单的直接重起服务就可以解决的。对于这种问题一些人可能会使用热备服务器去解决,当主缓存服务宕掉后,自动切换到备份缓存服务器,但是这样做 违背了缓存设计的初衷,正确的做法应该是使用分布式缓存,数据会被缓存在多台机器上,当某台机器不可用时只是部分数据不可用,重新启动即可。
- 缓存预热
缓存中存放的是热点数据,热点数据又是缓存系统利用LRU算法对不断访问的数据筛选淘汰出来的,这个过程需要花费较长的时间。新启动的缓存系统如果没有任何数据,在重建缓存数据过程中,系统的性能和数据库负载都不会太好,那么最好在缓存系统启动时就把数据加载好,这种手段叫缓存的预热。例如淘宝双十一,开发人员会提前一个月预热大量的缓存数据。
- 缓存穿透
对于访问数据库没有的数据,可能一些开发人员的做法是直接返回到前台,但是这种做法是不正确的。正确的做法应是将其key缓存起来value 设置为NULL即可。