Hbase读写操作
HDFS、MR解决了分布式存储和分布式计算问题,但是由于HDFS的随机读写能力太差,所以不能直接作为数据库。Hbase是为了应对这点而诞生的,它是一个高性能、高可靠、可伸缩、面向列的分布式存储数据库,结合Zookeeper可以解决HDFS随机读写能力差的问题。那么它到底是怎么解决随机读写能力太差的问题呢?试想一下如果想要1S 往某个文件中插入100条记录,如果没有HBase,用Java代码写会是一种什么样的操作?可能我们需要100次的IO才能搞定。但上面假设一层缓冲层用来缓存一下, 当缓冲池满了以后再往文件中写,会不会好很多?
以Mysql为例,我们都知道Mysql的表,库等数据最终都会落在磁盘上,Mysql只不过是架设在OS文件系统上的一款解析软件而已,帮准你用流完成文件的读写。HDFS相当于OS文件系统,HBase和Mysql一样相当于一个解析器。
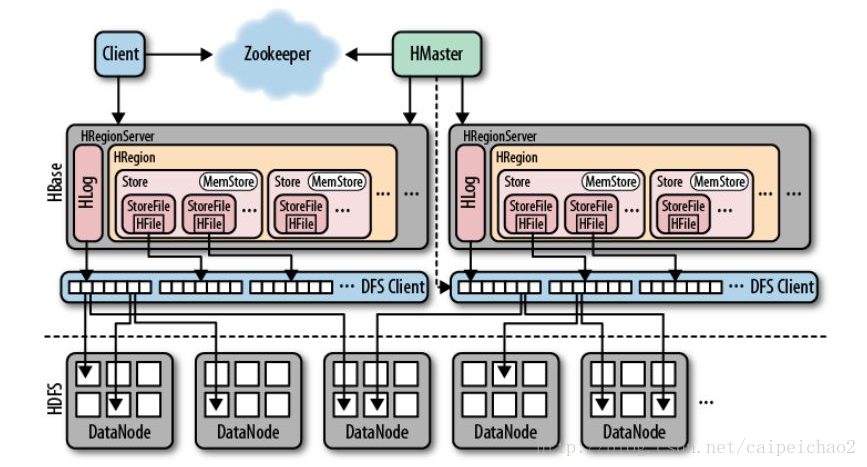
Hbase架构图
被网上的图片坑的很,HLog组件应该归属于HRegionServer管,但是图中却把HLog画到了HRegion中,也有可能是版本问题?

下面的图摘自《HBase权威指南》
写操作
当Client向HRegionServer发起put请求时,其将会交给对应的HRegion来处理
首先HRegion会看是否需要写入HLog(WAL用于做数据恢复和数据回滚)
当数据持久化到HLog后,数据会被直接写到MemStore中,并检查MemStore是否满了,如果满了,数据会被刷到HDFS上以HFile文件类型存储,这个操作由另一个HRegionServer的线程处理,同时会保存最后写入序号,系统就知道哪些数据被持久化了。
摘自《HBase权威指南》–8.2.2写路径
读操作
很纳闷为啥HBase权威指南里面没找到读数据的章节,下面摘自网络流转的说法,具体需要看一下源码验证
首先Client向HRegionServer发送Get请求,HRegion将其请求提交给对应的HRegion
HRegion会先从MemStore中找,如果找到则返回,如果没有或者数据不全,则去StoreFile中寻找