K-Means
机器学习三大类,监督学习、无监督学习和强化学习。K均值(K-Means)是无监督学习中的一种聚类算法,能有有效的将数据划分子类。
应用场景
打开新浪新闻首页,可以发现“要闻”一栏展示了目前最热门的一组新闻。类似的还有google news等

思路
以二维数据为例,描述一下k-means的实现思路:
1. 在二维平面区域内n个样本点中,首先任意选取m个点,称其为质心点
2. 对n个样本点和m个质心点求距离(欧式距离),找到每个样本点离得最近的质心点
3. 更新m个质心点的位置,重复第2步
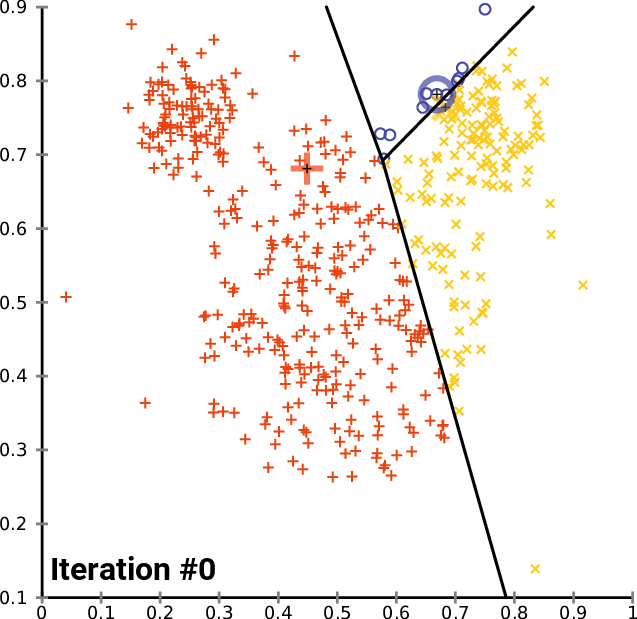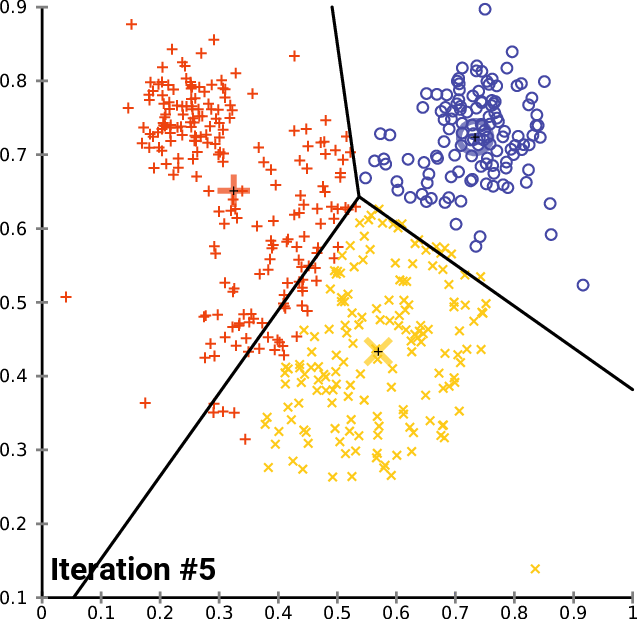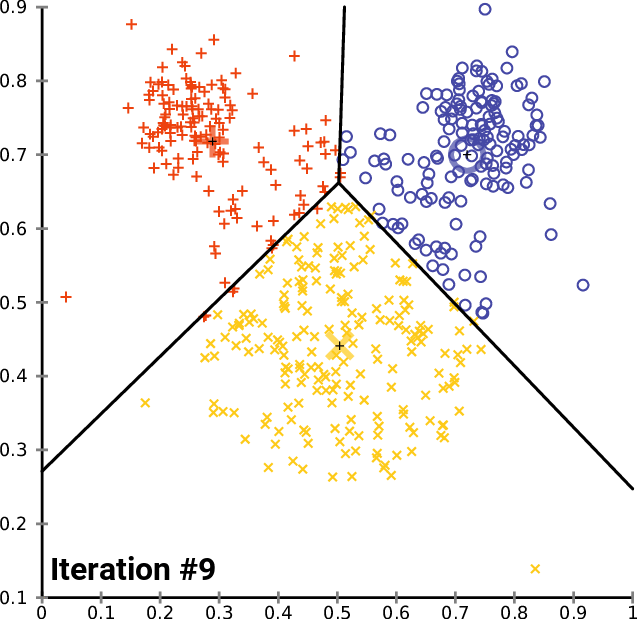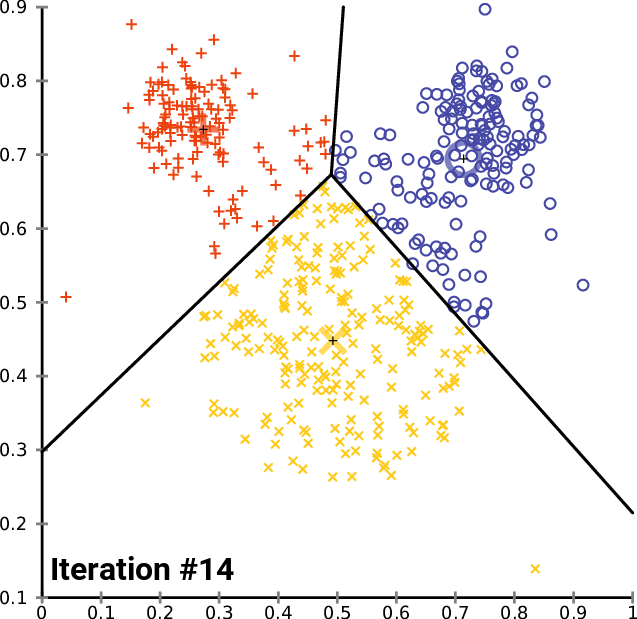
以下图为例,描述详细的划分流程
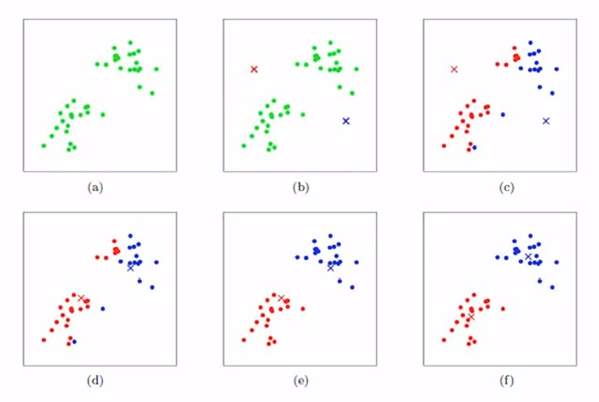
1. 在平面内n个样本点中,选2个质心点标记好x,对应b)
2. 分别对n个样本点和2个质心点求距离,找到每个样本点离得最近的质心点;对应图c)
3. 更新2个质心点的位置对应图d)
4. 重复第2步,找到每个样本点离得最近的质心点;对应图e)
5. 重复第2步,找到每个样本点离得最近的质心点;对应图f)
下面使用Python语言实现模型训练和预测,其中会使用到 numpy、matplotlib.pyplot、sklearn.datasets、scipy.spatial.distance,不熟悉的童鞋自行先去补一下,看起来事半功倍!
实现代码
思路:使用sklearn.datasets提供的数据来训练出模型。然后使用训练出的模型进行预测并验证模型的正确性!
引入依赖
1 | |
初始化数据
1 | |
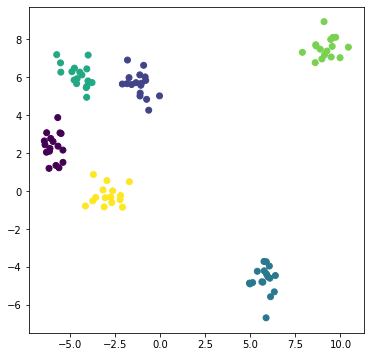
为了方便观察,我们画出图
1 | |
编写核心k-means代码,封装一个类K_Means
1 | |
测试,为了方便观察我们先封装一个画子图方法
1 | |
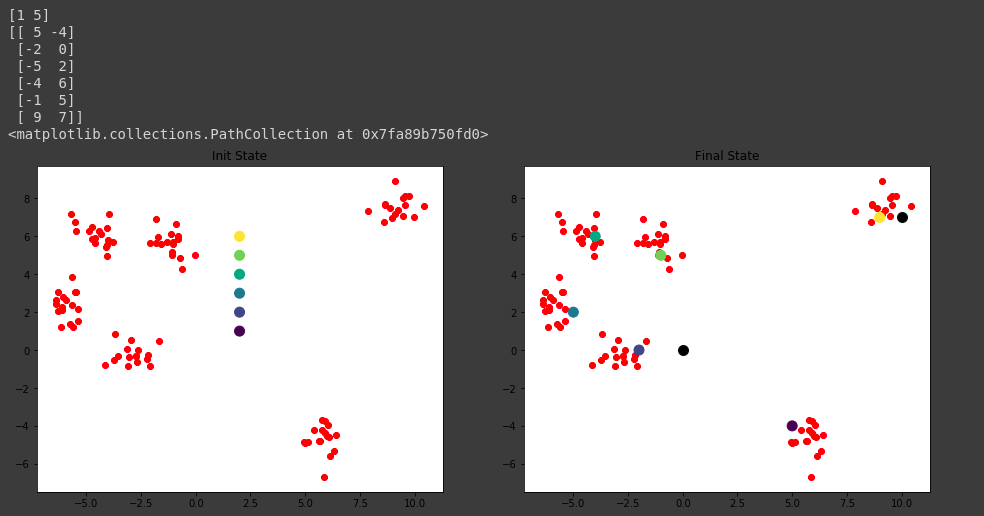
预测的结果是[0,0]属于1; [10,7]属于5,1对应的群组是质心点[-2,0]所在的群组,而5对应的群组是质心点[9,7]所在的群组,显然是正确的。
K-Means
http://example.com/2020/02/06/2020–02-06-K均值聚类/