首先我们构建一个jdk1.8+centos基础镜像,由于网上已经有很多现成的轮子,这里就不自己造了
1
| docker pull ryaning/centos-ssh
|
一、构建基础镜像
如果镜像下载不下来,可以使用下面方法自己创建基础镜像
1
2
3
|
# 编辑 Dockerfile
vi Dockerfile
|
新增以下内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| # 基础镜像
FROM ryaning/centos-ssh
# 作者
MAINTAINER Ryan <me@ryana.cn>
# 构建镜像
ADD jdk-8u162-linux-x64.tar.gz /usr/local/
RUN mv /usr/local/jdk1.8.0_162 /usr/local/jdk1.8
ENV JAVA_HOME /usr/local/jdk1.8
ENV PATH $JAVA_HOME/bin:$PATH
ADD hadoop-2.9.2.tar.gz /usr/local
RUN mv /usr/local/hadoop-2.9.2 /usr/local/hadoop
ENV HADOOP_HOME /usr/local/hadoop
ENV PATH $HADOOP_HOME/bin:$PATH
RUN yum install -y which sudo
|
二、 搭建hadoop集群
规划
准备搭建一个具有三个节点的集群,1 master 2 slave
- master: hadoop0 ip: 192.168.10.10
- salve1: hadoop1 ip: 192.168.10.11
- salve2: hadoop2 ip: 192.168.10.12
配置IP
docker 容器在启动时默认使用的是 bridge 模式,docker 容器启动后,会连接到一个名为 docker0 的虚拟网桥,故每次启动 docker 容器的 IP 都不是固定的,不方便管理,有时候需要进行固定 IP 映射,比如 docker 集群管理时。docker 在 1.9 版本版后,提供了创建自定义网络功能命令。
1
2
3
4
5
6
7
| # 创建自定义网络
# ip段为:192.168.10.1/24,名字为:hadoop
docker network create --subnet=192.168.10.1/24 hadoop
# 显示自定义网络列表
docker network ls
|
运行
运行3个 hadoop 容器,分别命名为 hadoop0,hadoop1,hadoop2,其中 hadoop0 作为 master, 并且映射了端口号,50070 和 8088,用来在浏览器中访问 hadoop WEB 界面的。
命令说明:
- -e TZ=”Asia/Shanghai” 增加环境变量,指定时区
- -v /etc/localtime:/etc/localtime:ro:挂载系统时间到容器内
- –net hadoop –ip 192.168.10.10:配置 Hadoop 集群节点的固定 IP
- –add-host hadoop1:192.168.10.11:除了需要配置好 Hadoop 集群节点的固定 IP 外,还需要修改 Hadoop 容器内部的 hosts 文件,设置主机名与 ip 的映射。在 docker 中直接修改 /etc/hosts 文件,在重启容器后会被重置、覆盖。因此需要通过容器启动脚本 docker run 的 –add-host 参数将主机和 ip 地址的对应关系传入,容器在启动后会写入 hosts 文件中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| # hadoop0
docker run --name hadoop0 \
--hostname hadoop0 \
--net hadoop --ip 192.168.10.10 \
--add-host hadoop1:192.168.10.11 \
--add-host hadoop2:192.168.10.12 \
-p 50070:50070 \
-p 8088:8088 \
-d -P ryaning/hadoop
# hadoop1
docker run --name hadoop1 \
--hostname hadoop1 \
--net hadoop --ip 192.168.10.11 \
--add-host hadoop0:192.168.10.10 \
--add-host hadoop2:192.168.10.12 \
-d -P ryaning/hadoop
# hadoop2
docker run --name hadoop2 \
--hostname hadoop2 \
--net hadoop --ip 192.168.10.12 \
--add-host hadoop0:192.168.10.10 \
--add-host hadoop1:192.168.10.11 \
-d -P ryaning/hadoop
|
设置 SSH 免密码登录
前面已经为容器配置 IP 了,在进行 ssh 时需要输入要登陆的容器的 root 密码,Hadoop 集群要求集群间机器 SSH 连接时无密码登陆,下面讲述容器间如何配置 SSH 无密码登陆。
以 hadoop0 容器为例,hadoop1、hadoop2 容器同样需要修改。
1
2
3
4
5
6
7
8
9
10
| # 进入 hadoop0 容器内
docker exec -it hadoop0 bash
# 执行后会有多个输入提示,不用输入任何内容,全部直接回车即可
ssh-keygen
# 执行命令后需要输入登录密码,**默认为 123456**
ssh-copy-id -i /root/.ssh/id_rsa -p 22 root@hadoop0
ssh-copy-id -i /root/.ssh/id_rsa -p 22 root@hadoop1
ssh-copy-id -i /root/.ssh/id_rsa -p 22 root@hadoop2
|
修改 Hadoop 配置文件
要想真正的运行 hadoop 应用还需要修改 hadoop 运行参数;以 hadoop0 为例,进入到容器内 /usr/local/hadoop/etc/hadoop 目录下,需要修改的可执行文件与配置文件包括:hadoop-env.sh、yarn-env.sh、core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml。
注释掉原有的配置 export JAVA_HOME=${JAVA_HOME},修改成当前的 export JAVA_HOME=/usr/local/jdk1.8。
1
| export JAVA_HOME=/usr/local/jdk1.8
|
同样是重新指定 export JAVA_HOME=/usr/local/jdk1.8。
1
2
3
|
export JAVA_HOME=/usr/local/jdk1.8
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| <configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop0:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
|
1
2
3
4
5
6
7
8
9
10
| <configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| <configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop0:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop0:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop0:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop0:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop0:8088</value>
</property>
</configuration>
|
这个文件默认不存在,需要从 mapred-site.xml.template 复制过来
1
| mv mapred-site.xml.template mapred-site.xml
|
1
2
3
4
5
6
| <configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
|
修改 hadoop0 中的从机(slaves)配置
1
2
|
vi /usr/local/hadoop/etc/hadoop/slaves
|
删除原来的所有内容,修改为如下
hadoop 集群配置分发
在 hadoop0 中执行命令,将 hadoop0 中的配置复制到其他两个节点中。
1
2
| scp -r /usr/local/hadoop hadoop1:/usr/local
scp -r /usr/local/hadoop hadoop2:/usr/local
|
三、启动
第一次启动集群时,需要初始化
初始化
1
2
3
| # 初始化
hdfs namenode -format
|
出现类似下面命令说明格式化成功。

注:格式化操作不能重复执行。如果一定要重复格式化,带参数 -force 即可。
启动 hadoop 集群
1
2
3
|
# /usr/local/hadoop 目录下执行
sbin/start-all.sh
|
注:在主节点 hadoop0 启动 hadoop,从节点 hadoop1、hadoop2 会自动启动。
浏览器中访问
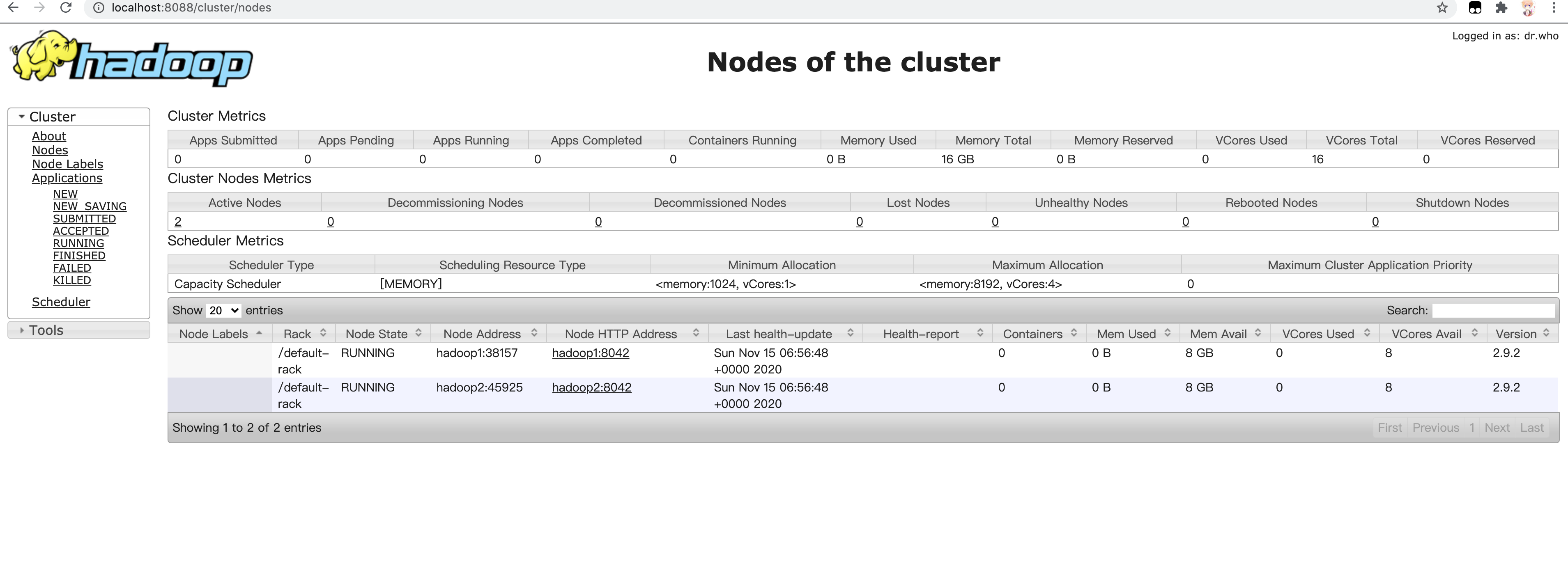
四、验证集群是否正常
可以正常访问的话,说明集群启动成功了,但不一定能正常运行,还需要下面的实际验证。
测试验证
创建本地测试文件,在 /opt 目录下创建测试文件目录。
1
2
3
| mkdir wcinput
cd wcinput
vi wc.input
|
wc.input文件内容如下:
1
2
3
4
5
| hadoop mapreduce
hadoop yarn
hadoop hdfs
mapreduce spark
hadoop hello
|
创建 HDFS 目录
1
| hdfs dfs -mkdir -p /user/hadoop/input
|
上传文件,把测试文件上传到刚刚创建的目录中
1
| hdfs dfs -put /opt/wcinput/wc.input /user/hadoop/input
|
查看文件上传是否正确
1
2
3
4
5
| hdfs dfs -ls /user/hadoop/input
[root@hadoop0 wcinput]# hdfs dfs -ls /user/hadoop/input
Found 1 items
-rw-r--r-- 1 root supergroup 70 2019-01-21 10:07 /user/hadoop/input/wc.input
[root@hadoop0 wcinput]#
|
运行 mapreduce 程序
hadoop 安装包中提供了一个示例程序,我们可以使用它对刚刚上传的文件进行测试
1
| hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /user/hadoop/input /user/hadoop/output
|
注:在执行过程中,如果长时间处于 Running 状态不动,虽然没有报错,但实际上是出错了,后台在不断重试,需要到 logs 目录下(/usr/local/hadoop/logs)查看日志文件中的错误信息。
查看输出结果
1
2
3
4
5
| hdfs dfs -ls /user/hadoop/output
[root@hadoop0 wcinput]# hdfs dfs -ls /user/hadoop/output
Found 2 items
-rw-r--r-- 1 root supergroup 0 2019-01-22 05:35 /user/hadoop/output/_SUCCESS
-rw-r--r-- 1 root supergroup 51 2019-01-22 05:35 /user/hadoop/output/part-r-00000
|
_SUCCESS 表示 HDFS 文件状态,生成的结果在 part-r-00000 中查看。
1
2
3
4
5
6
7
8
9
| hdfs dfs -cat /user/hadoop/output/part-r-00000
[root@hadoop0 wcinput]# hdfs dfs -cat /user/hadoop/output/part-r-00000
hadoop 4
hdfs 1
hello 1
mapreduce 2
spark 1
yarn 1
[root@hadoop0 wcinput]#
|
以上就是使用 Docker 环境搭建 Hadoop 镜像容器,配置 Hadoop 集群,并启动和测试的实例,测试用的是 hadoop 官方给的一个 wordcount 统计,利用 hadoop 安装包里的 mapreduce 示例 jar 计算指定 HDFS 文件里的单词数,并将结果输出到指定 HDFS 目录。后面会介绍 HDFS 常用文件操作命令。
links: https://book.ryana.cn/hadoop/docker-install-hadoop.html